Este texto foi motivado tanto pela recente série de artigos que estou postando aqui, na tentativa de mostrar como desenvolver uma aplicação mais “cientificamente correta” para microcontroladores de 8 bits (Atmel ATmega2560, num Arduino), quando pela confusão que continuo vendo por ai com relação ao uso de valores em ponto flutuante.
Já escrevi sobre ponto flutuante por aqui, algumas vezes, e continuarei a insistir no tema… É importante que o leitor entenda, de uma vez por todas, que um valor expressado em ponto flutuante não é um número “real” (no domínio 
Dividi esse texto em partes onde começo falando da relação entre frações e valores binários, passo pela estrutura da codificação do tipo de ponto flutuante de precisão simples (float) e termino mostrando um código equivalente da instrução FADD (ou, operador ‘+’ envolvendo 2 floats). Há uma observação sobre multiplicação, no final.
Valores binários com frações
A conversão de valores decimais inteiros para binários é velha conhecida de todos nós. É fácil descobrir que 12 pode ser escrito, em binário, como 1100. Mas, e quanto a valores como 0.15625?
Um número no domínio

Números binarios com componentes fracionárias podem ser escritos da mesma forma, só que a base será 2.
Qualquer valor com número limitado de algarismos “depois da vírgula” pode ser escrito como um valor inteiro. Em decimal, 0.15625 pode ser escrito como 
De novo, em binário é a mesma coisa. É prudente lembrar que, mesmo com aritmética inteira, lidamos com uma quantidade de bits limitada.
A estrutura de codificação de um float:
O tipo float tem 32 bits de tamanho e seus bits são estruturados assim:

O bit sign diz, é claro, se o valor armazenado é positivo ou negativo (0 é positivo e 1, negativo).
Logo depois temos 8 bits associados ao valor do expoente e da base 2 (explico abaixo).
Os 23 bits seguintes armazenam apenas a parte fracionária do valor binário. Ao invés de tratar as posições desses bits como estão na estrutura do float, gosto de pensar neles como posicionados na parte fracionária, assim:

Mais adiante veremos que essa parte fracionária geralmente é adicionada ao valor 1.0 para montar o que é conhecido como “mantissa” ou “significante”. Uma nota para os puristas: Algumas pessoas reclamam do termo “mantissa” porque é usado para expressar o resultado do cálculo de um logarítmo. No entanto, a palavra tem um significado mais amplo: É a parte significativa de um valor.
O conhecimento da estrutura do float é importante porque agora você sabe que:
- Não há como representar mais que 24 bits numa mantissa;
- A mantissa é sempre positiva. O bit de sinal é que muda o sentido do valor;
- Existe um limite de 8 bits para o expoente da base que será multiplicada pela mantissa.
Mais adiante falo sobre o famigerado valor FLT_EPSILON e como ele deve ser usado em comparações entre dois valores float.
Obtendo um número “quebrado” com 23 “casas binárias”:
Para encontrar o valor binário “real” basta multiplicarmos o valor decimal “real” por 
0.5 * (1 << 23) = 0.10000000000000000000000(2) π * (1 << 23) ≈ 11.00100100001111110110100(2) 0.15625 * (1 << 23) = 0.00101000000000000000000(2) 0.1 * (1 << 23) ≈ 0.00011001100110011001100(2)
Gráficamente coloquei um ponto para separar os 23 bits inferiores do valor inteiro obtido. Mas, não é interessante como esses 23 bits correspondem também à parte fracionária, em binário? É só somar todos os bits das posições n, fazendo 

Eis o valor 0.15625, os bits nas posições -3 e -5 estão setados, logo:

Simples, né?
Notação científica
Embora a conversão para valores binários “quebrados” seja simples, nas condificações de ponto flutuante temos apenas o valor fracionário. A parte inteira é omitida, ou menor, é implicita…
Em Física existe uma regra, ou norma, para escrevermos valores chamada notação científica. Todo número deve ser escrito no formato 

O processo de converter um valor qualquer para notação científica chama-se normalização (vem de “colocar na norma”… o que mais seria?). E todo valor que segue essa norma é dito estar normalizado.
Em binário, se usarmos a norma, o valor inteiro terá que ser, necessariamente, igual a 1 (a norma é clara: a parte inteira tem que ser sempre maior que zero e só pode ter um algarismo, portanto…).
Tipos de valores, em ponto flutuante:
Se todo valor binário “quebrado” tem que começar com 1, como é que é codificado 0.0?!
Bem… a norma nos dá a maioria dos números binários codificados num float… Na realidade, temos 3 tipos bem definidos de valores: Os normalizados (que são a maioria), os denormalizados (onde a parte inteira é 0.0) e os que não são números.
Com base na estrutura de um float, a fórmula de conversão de um valor binário para decimal, onde f é o valor decimal resultante, s é o bit de sinal , n é o valor da mantissa (parte inteira e a parte fracionária ‘bbbb…’) e E é o expoente (com base no valor de e, da estrutura acima):

Se e=0, temos um valor denormalizado. Isso significa que a mantissa é usada como está e o expoente E será -126. Valores denormalizados são usados para representar números bem pequenos. Esses valores devem ser evitados sempre que possível por dois motivos: O processador penaliza a performance da operação que envolva valores denormalizados, inserindo (no caso da arquitetura Intel) 1 ciclo de máquina extra e, o outro motivo, é que valores denormalizados têm 23 bits de precisão. Um a menos que os valores normalizados (que têm 24: Os 23 da parte fracionária e o valor 1, implícito, da parte inteira).
Existe uma exceção na faixa dos valores denormalizados: Já sabemos que usando valores normalizados não podemos escrever 0.0. Zero é um caso especial, onde n=0 e e=0. E, por estranho que pareça, existem dois zeros: +0 e -0.
Se tivermos o expoente e entre 1 e 254, temos um valor normalizado. Neste caso, o expoente E é dado pela fórmula E=e-127. É fácil notar que para termos E=0 temos que ter e=127 e que os expoentes mínimo e máximo nesse “fator multiplicativo” está entre -126 e 127.
Um exemplo: o valor 1.0, decimal, pode então ser escrito como:
sinal expoente mantissa 0 01111111 00000000000000000000000
O pequeno código abaixo te mostrará isso:
float x = 0.0f;
unsigned int *p = (unsigned int *)&x;
printf("%f -> [%d 0x%02X 0x%07X]\n",
x, *p >> 31, (*p >> 23) & 0xff, *p & 0x7fffff);
Existe um caso especial, onde e = 255. A mantissa perde o propósito de manter um valor e o número codificado no float passa a ser um não-número. Esse não-número pode ser interpretado como 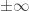
A diferença entre infinitos e NaN é o conteúdo da mantissa… mantissa zerada nos dá um dos infinitos, mantissa com alguma coisa (qualquer coisa) nos dá NaNs.
Lembre-se que, mesmo na matemática, valores infinitos não são “números”… Assim, somar +1 a 
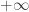
Um alerta sobre arredondamentos:
Embora floats tenham precisão de 24 bits para valores normalizados, o processador mantém um 25º bit chamado bit de guarda. Esse bit é usado nas rotinas internas de arredondamento. Para entender como, temos que recorrer ao velho método de arredondamento de valores inteiros…
Se você tem um valor como 1.7 e quer arredondá-lo para um inteiro pode, essencialmente, fazer uma de duas coisas: Ou ignora a parte fracionária (processo chamado de truncamento) ou adiciona 0.5 à parte inteira e depois ignora a parte fracionária do resultado.
O bit extra, escondido, que o processador mantém é usado justamente para manter uma precisão um pouco maior (

O conceito de ULP é diferente de epsilon (letra grega ε). Epsilon é o valor do último bit da mantissa, ou seja, 
bool iguais = (fabsf(a - b) >= FLT_EPSILON);
Para a e b muito pequenos e com grandezas muito inferiores ao valor de FLT_EPSILON… Outro macete popular é fazer:
float A = fabsf(a), B = fabs(b); float maior = (B > A) ? B : A; bool quaseiguais = (fabs(a - b) <= maior * FLT_EPSILON);
Que é um pouco melhor. Ao multiplicarmos o maior valor absoluto por FLT_EPSILON estamos obtendo um valor na grandeza de um ULP (levando em conta o valor do expoente). Assim, se a diferença entre os valores for inferior que esse valor “mínimo”, os valores podem ser considerados “quase” iguais.
Se você precisa comparar dois valores contra a menor exatidão possível, o método correto é obter a escala do maior valor (pode ser obtida via fumção frexpf) e multiplicá-la por FLT_EPSILON para obter o valor de 1 ULP… Parecido com o macete acima:
int e; float A = fabsf(a), B = fabs(b); float maior = (B > A) ? B : A; frexpf(maior, &e); bool quaseiguais = (fabs(a - b) <= ldexpf(FLT_EPSION, e));
Adição e subtração
Como a mantissa pode ser tratada como se fosse um valor inteiro de 24 bits, bastando adequar o expoente da base 2, as operações elementares podem ser feitas como se esses valores fossem inteiros. Em decimal, 


Existe um detalhe chato: Já que quando tivermos potências diferentes teremos que equalizá-las antes de efetuar a adição (ou subtração) e temos dois valores, qual deles deve ser alterado? Se fizermos isso com o menor valor, precisaremos multiplicá-lo por 2n até que os expoentes sejam iguais. Isso implica em deslocar a mantissa para a direita (aumentando a grandeza do menor valor)… Só que temos apenas 24 bits na mantissa! Os bits inferiores serão perdidos no processo… Do outro lado, se adequarmos o maior valor ao menor manteremos a mesma quantidade de bits na parte fracionária nos dois valores. Assim, sempre devemos adequar o maior dos dois valores.
Outro detalhe: Se na equalização de expoentes o deslocamento necessário for maior que 23 bits, o menor valor pode ser seguramente ignorado, encarado como se fosse 0.0, já que sua significância é inferior a
float a = 1e30, b = 1.0f; float c, d; c = a + b - a; // isso é 0.0f d = a - a + b; // isso é 1.0f
Ao somar 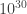
Aprendam isso: Em muitos casos a adição (e subtração) não é comutativa! Isso significa que a ordem com que as adições são feitas é importante!
A listagem à seguir mostra um código de emulação da instrução fadd, quase em conformidade com a especificação IEEE 754 (falta o detalhe de arredondamento!) usando tudo o que expliquei acima:
/*
* fp.c
*
* Rotinas que emulam o processo de adição realizado pela
* ALU do microprocessador. A única coisa que parece estar
* faltando são as rotinas de arredondamento e o bit
* de guarda. A rotina funciona para toda a faixa dos floats.
*
* ---------------------
* A estrutura de um float é (do MSB para o LSB):
*
* 1 bit: sinal;
* 8 bits: expoente;
* 23 bits: mantissa.
* ---------------------
*/
#include <stdio.h>
#include <stdint.h>
/* Protótipos das rotinas auxiliares.
_join e _split juntam e separam as partes de um float.
_fswap troca dois floats de lugar.
Elas têm o atributo noinline para que fadd() não fique muito
grande. Assim, o código em assembly, gerado pelo compilador
poderá ficar um pouco mais compreensível.
Internamente, o processador separa e junta os componentes de
um float através de circuitos lógicos. É provável que ele tenha
"registradores" internos de 23 bits para a parte fracionária,
registradores de 8 bits para o expoente e um único bit para o sinal.
_join e _split servem apenas para adequar os tipos acessíveis
a nós para a emulação. _fswap poderia ser inline...
*/
float _join(int, uint8_t, uint32_t)
__attribute__((noinline));
void _split(float, int *, uint8_t *, uint32_t *)
__attribute__((noinline));
void _fswap(int *, uint8_t *, uint32_t *,
int *, uint8_t *, uint32_t *)
__attribute__((noinline));
/* Rotina que faz a+b, com floats normalizados. */
float fadd(float a, float b)
{
int sa, sb, sub_flag;
uint8_t ea, eb;
short et; /* NOTA: O expoente temporário precisa de
mais que 8 bits. */
uint32_t ma, mb;
uint64_t mt; /* NOTA: mt tem 64 bits de tamanho
para permitir o shift para a
esquerda. */
/* Separa os floats em suas partes. */
_split(a, &sa, &ea, &ma);
_split(b, &sb, &eb, &mb);
/* Ordena os valores de forma que 'a' será sempre maior
que 'b'. */
if (eb > ea || mb > ma)
_fswap(&sa, &ea, &ma, &sb, &eb, &mb);
/* Sinais opostos significa subtração! */
sub_flag = sa ^ sb;
/* Trata casos especiais (inf e NaN). */
if (!ea && !ma) return b; /* FIX: Se a==0, retorna b. */
if (!eb && !mb) return a; /* FIX: Se b==0, retorna a. */
if (ea == 255)
{
/* Se ambos os valores forem inifinitos com sinais
opostos, volta 0.0, senão retorna o inifinito com o
sinal de a. */
if (ma == 0 && (eb == 255 && mb == 0) && sub_flag)
return _join(0, 0, 0);
else
return _join(sa, 255, 0);
/* Se um dos valores for NaN, retorna NaN. */
if (ma || (eb == 255 && mb))
return _join(sa, 255, ma | mb);
}
/* Coloca o bit implícito nas mantissas.
Faz isso apenas se o expoente não for 0,
ou seja, se o valor for normalizado. */
if (ea) ma |= 0x800000;
if (eb) mb |= 0x800000;
/* Copia a mantissa e expoente do maior valor
para variáveis maiores! */
mt = ma;
et = ea;
/* Se os valores têm expoentes diferentes, temos que
equalizá-los. */
if (ea != eb)
{
int diff;
/* Calcula a diferença de expoentes.
Se for muito grande, ignora b. */
if ((diff = ea - eb) > 24)
return _join(sa, ea, ma);
/* Caso contrário, adequa os expoentes, e
faz p shift de 'a'. */
mt = (uint64_t)ma << diff;
et -= diff;
/* Neste ponto os valores estão com os expoentes
equalizados. */
}
/* Realiza a adição. */
if (!sub_flag)
{
/* Ao adicionar dois valores normalizados, teremos,
na parte inteira, em binário: 1+1 = 10. O que torna
necessário o deslocamento de 1 bit para a direita! */
mt = (mt + mb) >> 1;
et++; /* Ajusta expoente. */
}
else
mt -= mb;
/* Normaliza o resultado. */
while (mt & 0xff000000)
{
mt >>= 1;
et++;
}
/* Se o expoente final é muito grande, retorna Inf ou -Inf.
Acredito que o expoente jamais será 0 depois da
normalização. Tenho que testar isso! */
if (et > 254)
{
sa = (et < 0);
et = 255;
mt = 0;
}
/* Junta o float em suas partes. */
return _join(sa, et, mt);
}
/* ------------ As rotinas auxiliares ---------------- */
/* Separa um float em suas partes. */
void _split(float x, int *sign, uint8_t *exp,
uint32_t *mantissa)
{
uint32_t *p = (uint32_t *)&x;
*sign = *p >> 31; /* Pega o sinal. */
*exp = (*p >> 23) & 0xff; /* Pega o expoente. */
*mantissa = *p & 0x7fffff; /* Pega a fração. */
}
/* Junta as partes de um float. */
float _join(int sign, uint8_t exp, uint32_t mantissa)
{
float x;
uint32_t *p = (uint32_t *)&x;
*p = sign ? 0x80000000 : 0; /* Ajusta sinal. */
*p |= (uint32_t)exp << 23; /* Posiciona o expoente. */
*p |= mantissa & 0x7fffff; /* Ajusta a fração. */
return x;
}
/* É a mesma coisa que:
void _fswap(float *a, float *b)
{ float t=*a; *a=*b; *b=t; }
*/
void _fswap(int *sa, uint8_t *ea, uint32_t *ma,
int *sb, uint8_t *eb, uint32_t *mb)
{
int stmp;
uint8_t etmp;
uint32_t mtmp;
mtmp = *ma;
etmp = *ea;
stmp = *sa;
*ma = *mb;
*ea = *eb;
*sa = *sb;
*mb = mtmp;
*eb = etmp;
*sb = stmp;
}
Um aviso: O código acima ainda pode ter erros com relação a valores de-normalizados. Não tive paciência de fazer testes exaustivos. No entanto ele ilustra as complexidades de uma simples adição (ou subtração) de dois valores do tipo float.
Multiplicações e divisões:
Por incrível que pareça, multiplicar e dividir é bem mais simples que somar e subtrair. Isso vem do fato de que podemos multiplicar as mantissas e depois somar os expoentes, seguido de normalização e obteremos o resultado desejado. Na divisão os expoentes são subtraídos… Geralmente essas operações são mais lentas que a adição porque multiplicação e divisão inteira são implementadas em função de adições e subtrações (multiplicação é uma sucessão de adições e divisões é uma sucessão de subtrações). Mesmo que o algoritmo seja bem otimizado ou use algum macete esotérico, os algoritmos ainda usarão adições e subtrações…
Diferente das adições, a exatidão do resultado não está atrelada à precisão do maior valor. O ULP de um valor como 1.0 é de 
O que deixei de fora?
Sinto que a coisa mais importante que deixei de fora desse texto foi o cálculo de estabilidade de equações usando ponto flutuante. É um assunto interessante… Mas, é o tipo de análise que exige algum nível de abstração matemática acima da média. Gastaria MUITO tempo e esforço (já reescrevi este artigo umas 5 vezes, por exemplo). Em outra opotunidade mostro como isso deve ser feito… Aconselho a leitura de um dos materiais que considero essenciais, chamado “What every computer scientist should know about floating point”, de David Goldberg, disponível para download aqui. E este livro aqui também é muito bom…
