Neste artigo vou tentar mostrar 3 coisas: O algoritmo mais óbvio raramente é o melhor possível, um bom algoritmo pode ser sempre melhorado e que essa melhoria nem sempre vem sem custos. A ideia é usar um algoritmo custoso, em termos de processamento e, para isso, aqui vão os famosos testes para determinação se um valor inteiro positivo é ou não um número primo.
Nesses testes usarei o tipo unsigned int porque ele tem 32 bits de tamanho em ambas as plataformas Linux (e na SysV ABI) e Windows, tanto para o modo de operação do processador, x86-64 e i386. É bom reparar nisso, porque a determinação desse tipo de parentesco (se é primo!) em valores inteiros com mais bits pode ser muito demorada. Por exemplo, quando lidamos com o esquema de criptografia assimétrica, é comum o uso de chaves de 2048 bits de tamanho, o que torna uma das otimizações inviável (veremos adiante).
O feio
O algoritmo clássico é varrer toda a faixa de valores menores que o valor sob teste e verificar se existe algum divisor exato. Algo assim:
// Método tradicional: Tenta dividir todos os valores
// inferiores a 'n' e conta quantos o dividem...
NOINLINE
int ugly_is_prime ( unsigned int n )
{
unsigned int count, i;
// caso especial.
if ( !n )
return 0;
count = 1;
for ( i = 2; i < n; i++ )
if ( ! ( n % i ) )
count++;
return (count == 1);
}
Por que chamei essa rotina de “o feio”? Ela testa por todos os valores inferiores a n, começando por 2, se n for diferente de zero! Suponha que  . Esse valor é primo, mas para a rotina determinar isso terá que percorrer todos os valores entre 2 e 4294967290. Veremos que, para isso, a rotina gasta cerca de 47 bilhões de ciclos de clock!
. Esse valor é primo, mas para a rotina determinar isso terá que percorrer todos os valores entre 2 e 4294967290. Veremos que, para isso, a rotina gasta cerca de 47 bilhões de ciclos de clock!
O mau
É claro que não precisamos verificar todos os valores! Por exemplo, 2 é o único valor par que também é primo. De cara podemos testar se n é par e diferente de 2. Se for, com certeza não é primo. Isso nos deixa os valores ímpares para teste, o que diminui pela metade o esforço computacional.
Outra melhoria que podemos fazer é a de que, de acordo com o Princípio fundamental da aritmética, todo número pode ser fatorado em números primos… Por exemplo,  ,
,  ,
,  e assim por diante (voltaremos a isso no algoritmo “bom”). Ainda, “lembre-se que a ordem dos fatores não altera o produto”. Tome 10 como exemplo… Ele pode ser escrito como
e assim por diante (voltaremos a isso no algoritmo “bom”). Ainda, “lembre-se que a ordem dos fatores não altera o produto”. Tome 10 como exemplo… Ele pode ser escrito como  .
.
Não é evidente, mas graças a isso só precisamos testar por divisores ímpares menores ou iguais a raiz quadrada de n:
// Método "ruim" (mas, melhor que o acima).
// Faz a mesma coisa, mas só verifica os valores inferiores a 'n'
// que sejam ímpares e menores ou iquais a raiz quadrada de 'n'.
int bad_is_prime ( unsigned int n )
{
unsigned int sr;
unsigned int i;
// casos especiais.
switch ( n )
{
case 1:
case 2:
return 1;
};
// O único par primo é 2.
if ( ! ( n & 1 ) )
return 0;
// Obtém o valor ímpar menor ou igual
// à raíz quadrada de n.
sr = sqrt(n);
if ( ! ( sr & 1 ) )
sr--;
// Só precisamos testar os valores ímpares
for ( i = 3; i <= sr; i += 2 )
if ( ! ( n % i ) )
return 0;
return 1;
}
Aqui tomo um atalho para os 2 primeiros primos (1 e 2) para simplificar a rotina.
Mas, porque essa rotina é má? O problema aqui é que, mesmo eliminando testes, estamos testando muitos valores mais de uma vez… Por exemplo, se n não for divisível por 3 ele também não será para nenhum múltiplo de 3, como 9, 12, 15, 18, 21, 24, 27… No entanto, estamos testando esses valores também, se n for grande!
O bom
A solução, é claro, é eliminar todos os valores múltiplos dos anteriores, ou seja, usar apenas divisores primos. O problema é óbvio: Ora, bolas! Como é que eu vou fazer uma rotina que testa se um valor é primo usando como critério o teste se um divisor também o é?!
O método de Erastótenes (276 AEC ~ 194 AEC) mantém uma sequência onde marcamos os valores primos, percorrendo a lista do início ao fim, e verificando se os próximos valores são múltiplos. Se forem, marcamos como “não primo”. Na próxima interação, o próximo valor é, com certeza, primo e repetimos o processo, até que todo o array contenha apenas os primos “não marcados”. Isso exige que toda a faixa de valores seja colocada no array, mas os valores usados como base de testes podem ser limitados à valores menores ou iguais a raíz quadrada de n, como fizemos anteriormente.
O ponto negativo desse método, é claro, é o consumo excessivo de memória para conter todo o array, mas, e se mantivéssemos apenas um array com os valores primos ímpares inferiores ou iguais à raiz quadrada da faixa do tipo unsigned int? Isso não consumirá tanta memória quanto você pode imaginar: Em primeiro lugar, no pior caso, teríamos um array com  itens. Se cada item tem 4 bytes de tamanho, aproximadamente 128 KiB serão usados para o array. No caso mais prático, vários valores desses 32767 são eliminados, porque não serão primos.
itens. Se cada item tem 4 bytes de tamanho, aproximadamente 128 KiB serão usados para o array. No caso mais prático, vários valores desses 32767 são eliminados, porque não serão primos.
O programinha abaixo, que usa o bad_is_prime(), acima, monta esse array:
// gentable.c
//
// Cria tabela contendo os inteiros, primos, menores ou iguais ao
// valor ímpar mais pŕoximo (porém menor) que a raiz quadrada de 2³²-1.
//
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
extern int bad_is_prime ( unsigned int );
#define ITEMS_PER_LINE 16
void main ( int argc, char *argv[] )
{
FILE *f;
unsigned int i, sr;
unsigned int count = 0, cnt2 = 0;
if ( ! *++argv )
{
fputs ( "Usage: gentable <cfile>\n", stderr );
exit ( 1 );
}
if ( ! ( f = fopen ( *argv, "wt" ) ) )
{
fprintf ( stderr,
"ERROR opening file %s for writing.\n",
*argv );
exit ( 1 );
}
fputs ( "// *** criado por gentable.c ***\n\n"
"// tabela começa de 3...\n"
"const unsigned int primes_table[] = {\n", f );
// ~0U é o máximo valor de unsigned int.
// Obtém a raiz quadrada ímpar...
sr = sqrt(~0U);
if (!(sr & 1))
sr--;
// Só precisamos dos inteiros ímpares e primos.
for ( i = 3; i <= sr; i += 2 )
if ( bad_is_prime ( i ) )
{
if ( count )
{
fputc( ',', f );
if (++cnt2 == ITEMS_PER_LINE)
{
fputc ( '\n', f );
cnt2 = 0;
}
else
fputc ( ' ', f );
}
fprintf ( f, "%uU", i );
count++;
}
fprintf ( f, "\n};\n\n"
"// tabela ocupa %zu bytes.\n"
"const unsigned int primes_table_items = %u;\n",
sizeof ( unsigned int ) * count,
count );
fclose ( f );
}
Basta compilar e executar o programinha para gerar um arquivo texto contendo o código fonte de uma tabela com apenas as raízes quadradas desejadas! No caso, gerarei table.c que, como pode ser observado, contém 6541 valores, ocupando apenas 25.5 KiB:
// *** criado por gentable.c ***
// tabela começa de 3...
const unsigned int primes_table[] = {
3U, 5U, 7U, 11U, 13U, 17U, 19U, 23U,
29U, 31U, 37U, 41U, 43U, 47U, 53U, 59U,
61U, 67U, 71U, 73U, 79U, 83U, 89U, 97U,
...
... 65447U, 65449U, 65479U, 65497U, 65519U, 65521U
};
// tabela ocupa 26164 bytes.
const unsigned int primes_table_items = 6541;
Para essa tabela de raízes o processamento é rápido. Considere o caso de valores de 64 bits. A máxima raiz quadrada é 4294967295. Como verificar se um valor é primo é relativamente lento, pré-calcular toda a tabela pode demorar um bocado… Existe ainda o fator espaço, que explico abaixo.
Usando essa tabela, a nossa rotina de teste good_is_prime fica assim:
extern const unsigned int primes_table[];
extern const unsigned int primes_table_items;
// Método "melhor": Faz quase a mesma coisa que acima, mas
// usa uma tabela pré calculada.
int good_is_prime ( unsigned int n )
{
unsigned int i, sr, *p;
switch ( n )
{
case 1:
case 2:
return 1;
}
if ( ! ( n & 1 ) )
return 0;
sr = sqrt(n);
for ( i = 0, p = (unsigned int *)primes_table;
i < primes_table_items && *p <= sr;
i++, p++ )
{
if ( ! ( n % *p ) )
return 0;
}
return 1;
}
Ela é bem parecida com bad_is_prime, mas usa uma tabela contendo apenas valores primos para os testes!
Nem sempre usar tabelas pré-calculadas é uma boa ideia
Em primeiro lugar, poderíamos usar uma tabela pré-calculada com todos os valores primos na faixa e a rotina final poderia ser uma simples busca binária, daí a performance da rotina seria proporcional a  , mas é claro que a tabela final seria enorme. Daí, escolhi armazenar apenas os valores que serão usados para verificar o divisor, eliminando os múltiplos…
, mas é claro que a tabela final seria enorme. Daí, escolhi armazenar apenas os valores que serão usados para verificar o divisor, eliminando os múltiplos…
A quantidade de valores primos, dado um valor máximo, pode ser aproximado (de longe!) por:

Assim, se quisermos montar uma tabela com todos os primos inferiores ou iguais à raiz quadrada do maior valor possível para um tipo, como no exemplo de unsigned int (que assume o valor máximo de 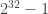 ), temos que o maior valor para a tabela é
), temos que o maior valor para a tabela é  e, portanto, usando a aproximação acima, teríamos uma tabela com cerca de 17171 itens. Cada item cabe em 2 bytes (unsigned short), já que
e, portanto, usando a aproximação acima, teríamos uma tabela com cerca de 17171 itens. Cada item cabe em 2 bytes (unsigned short), já que  . O que nos daria um array de, no máximo, 33.5 KiB. Se usarmos unsigned int (como fiz) o array estimado ficaria com 67 KiB.
. O que nos daria um array de, no máximo, 33.5 KiB. Se usarmos unsigned int (como fiz) o array estimado ficaria com 67 KiB.
Observe o contraste com o que encontramos através de gentable.c… Temos menos da metade dessa quantidade! Mas isso não é garantido! Temos que assumir que a aproximação acima é uma quantidade média e usarmos como critério para estimar o custo da rotina.
Considere agora, 64 bits. Usando o mesmo critério,  , que cabe num unsigned int. Daí
, que cabe num unsigned int. Daí  itens com 4 bytes cada, ou seja, quase 2 GiB de array. Repare que dobramos o número de bits da faixa sob teste, mas o tamanho da tabela aumentou quase de 29 mil vezes.
itens com 4 bytes cada, ou seja, quase 2 GiB de array. Repare que dobramos o número de bits da faixa sob teste, mas o tamanho da tabela aumentou quase de 29 mil vezes.
Isso é esperado porque a estimativa é exponencial (proporcional a  )… Então, não recomendo o método good_is_prime para valores com mais de 32 bits.
)… Então, não recomendo o método good_is_prime para valores com mais de 32 bits.
O quão bom é o “bom”?
No pior caso bad_is_prime é 10 milhões de vezes mais rápida que ugly_is_prime e good_is_prime é quase 4 vezes mais rápida que bad_is_prime (o que faz dela quase 40 milhões de vezes mais rápida que ugle_is_prime).
Estou informando esses valores, mas os medi, usando meu “contador de ciclos do homem pobre” em alguns casos:
- Melhor caso: Um valor não primo pequeno;
- Pior caso: Um valor primo muito grande: 4294967291
- Um valor não primo grande cujos fatores sejam primos grandes: 144795733, por exemplo, pode ser fatorado em 12343 e 11731.
Em alguns casos, no “melhor caso” e somente às vezes, bad_is_prime ganha de good_is_prime, mas isso ocorre, provavelmente, por causa dos efeitos do cache L1 (que só tem 32 KiB!). Isso, talvez, possa ser compensado fazendo um prefetch da tabela antes de executar a rotina… Esse é especialmente o problema quando o valor não é primo! Quando a rotina precisa varrer grande parte do o array os efeitos do cache L1 entram em ação e ela fica um pouco mais lenta que a “má” rotina…
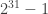







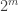











 ou do
ou do  . A solução mais “simples” é simplesmente dividir o comprimento (width) pela altura (height) e comparar o resultado com uma fração de ‘meio termo”. O “meio termo”, é claro, é a média aritmética simples dos dois aspectos:
. A solução mais “simples” é simplesmente dividir o comprimento (width) pela altura (height) e comparar o resultado com uma fração de ‘meio termo”. O “meio termo”, é claro, é a média aritmética simples dos dois aspectos:
 , então encaro o vídeo como candidato para ser convertido para letterbox, ao invés de widescreen. Ahhh… sim… note que o operador de comparação (<=) tem menor precedência que o de divisão (/)… Por isso a expressão intera faz o que queremos!
, então encaro o vídeo como candidato para ser convertido para letterbox, ao invés de widescreen. Ahhh… sim… note que o operador de comparação (<=) tem menor precedência que o de divisão (/)… Por isso a expressão intera faz o que queremos! , nem a divisão
, nem a divisão  , necessariamente, que é muito próximo de
, necessariamente, que é muito próximo de  ).
).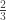 é maior que
é maior que 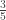 ? A solução que você aprendeu lá no ensino fundamental é converter ambas as frações ao mesmo denominador. Daí podemos comparar diretamente os numeradores, certo? Basta multiplicar ambos o numerador e o denominador de ambas as frações pelo denominador da outra fração:
? A solução que você aprendeu lá no ensino fundamental é converter ambas as frações ao mesmo denominador. Daí podemos comparar diretamente os numeradores, certo? Basta multiplicar ambos o numerador e o denominador de ambas as frações pelo denominador da outra fração:


 . No caso da parte fracionária, os fatores multiplicadores dos bits são da ordem de
. No caso da parte fracionária, os fatores multiplicadores dos bits são da ordem de 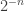 . O expoente negativo indica que o valor de cada bit deverá ser dividido pela potência de dois. A operação inversa, então, é multiplicar o valor decimal fracionário por 2 e obter o valor inteiro que, necessariamente, será 0 ou 1. No caso,
. O expoente negativo indica que o valor de cada bit deverá ser dividido pela potência de dois. A operação inversa, então, é multiplicar o valor decimal fracionário por 2 e obter o valor inteiro que, necessariamente, será 0 ou 1. No caso,  . Obtivemos 0, na parte inteira, e 0.28318 na parte fracionária… Esse 0, inteiro, é o MSB da parte fracionária… No segundo passo, multiplicamos apenas a parte fracionária resultante (0.28318) por 2. A parte inteira do resultado é o próximo bit e repetimos tudo para os próximos bits (eis todos os cálculos para 25 bits):
. Obtivemos 0, na parte inteira, e 0.28318 na parte fracionária… Esse 0, inteiro, é o MSB da parte fracionária… No segundo passo, multiplicamos apenas a parte fracionária resultante (0.28318) por 2. A parte inteira do resultado é o próximo bit e repetimos tudo para os próximos bits (eis todos os cálculos para 25 bits):
 e
e  :
:

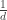 resultará num valor em ponto flutuante e queremos evitar isso… Para resolver esse problema, vajamos o que acontece quanto calculamos
resultará num valor em ponto flutuante e queremos evitar isso… Para resolver esse problema, vajamos o que acontece quanto calculamos  e teremos:
e teremos:
 por
por  em ponto flutuante, na verdade estaremos multiplicando o valor 10324441 (ou seja:
em ponto flutuante, na verdade estaremos multiplicando o valor 10324441 (ou seja:  ) e depois realizamos um shift para a direita de 27 bits. O único problema aqui é que float não tem precisão suficiente para a multiplicação de valores arbitrários para
) e depois realizamos um shift para a direita de 27 bits. O único problema aqui é que float não tem precisão suficiente para a multiplicação de valores arbitrários para  é que o quociente de divisão de valores positivos é
é que o quociente de divisão de valores positivos é  , enquanto para
, enquanto para  temos
temos  .
.

Você precisa fazer login para comentar.