Sempre topo com essa questão em foruns e mídias como o Discord: Como usar funções da biblioteca padrão de C em códigos puramente escritos em assembly? É “fácil”, mas eu não recomendo. Primeiro mostrarei como, usando o NASM e o GCC e depois digo o por quê da não recomendação. Eis um “hello, world” simples:
; test.asm
; Compile com:
; nasm -felf64 -o test.o test.asm
bits 64
; A glibc exige "RIP relative addressing".
; De qualquer maneira, isso é sempre uma boa
; prática no modo x86-64.
default rel
section .rodata
msg:
db `hello, world`,0
section .text
; Este símbolo está na glibc!
extern puts
global main
main:
; Chama puts(), passando o ponteiro da string.
lea rdi,[msg]
call puts wrt ..plt
; return 0;
xor eax,eax
ret
$ nasm -felf64 -o test.o test.asm
$ gcc -o test test.o
$ ./test
hello, world
Simples assim. O gcc deve ser usado como linker porque ele sabe onde a libc está.
O wrt ..plt é um operador do NASM chamado With Referece To. Ele diz que o símbolo está localizado em uma section específica. No caso a section ..plt, que contém os saltos para as funções da libc (late binding). Isso é necessário, senão obterá um erro de linkagem porque o linker não encontrará o símbolo… PLT é a sigla de “Procedure Linkage Table“. É uma tabela com ponteiros para as funções carregadas dinamicamente da libc.
Eis o porque de minha não recomendação: O compilador nem sempre usa o nome “oficial” da função, que pode ser um #define num header e, ás vezes, existem argumentos adicionais “invisíveis” para certas funções “intrínsecas”, mas o principal argumento contra essa prática é que seu código não ficará menor ou mais rápido só porque você está usando assembly. Por exemplo, ambos os códigos em C e Assembly, acima, fazem exatamente a mesma coisa e têm o mesmíssimo tamanho final (6 KiB, extirpando os códigos de debbugging e stack protection, no caso de C).
De fato, é provável que você crie um código em assembly pior do que o compilador C criaria…
Addedum: Não recomendo, particularmente, que se tente escrever códigos em assembly que usem a libc no ambiente Windows. O problema é que Windows coloca algum código adicional nas funções. Por exemplo, A pilha deve ser alterada para acomodar SEH (Structured Exception Handling), no caso de main, é necessário chamar uma função chamada _main… Coisas assim são problemáticas para o novato.
Já reparou nisso? Se você pede para dimensionar seus vídeos com número ímpar de linhas ou colunas o ffmpeg (e outros encoders) reclamam. Ainda, às vezes, quando você edita seu vídeo dimensionado dessa forma, ou observa colunas ou linhas pretas adicionadas no lado direito ou abaixo, ou linhas com “lixo” (um padrão de pixels maluco)… Isso acontece porque vídeos codificados com o padrão YUV 4:2:0 (ou NV12, por exemplo) ou qualquer um dos padrões YUV exigem que 4 pixels sejam agrupados juntos (2 pixels horizontais versus 2 pixels verticais) e, portanto, sua resolução tem que ter componentes pares.
Outro detalhe é relativo aos codecs. Se você usa um dos dois mais populares: h264 ou h265, cada quadro é dividido em blocos de pixels de tamanho (horizontal e vertical) múltiplos de (4×4, 8×8, 16×16 ou, no caso do h265, outros tamanhos múltiplos de ). Isso significa, de novo, que a imagem precisa ter dimensionamento par nos dois sentidos.
De novo esse troço? Well… Info para os aficionados por vídeos: Existem vários padrões de tamanho!
Os padrões mais simples de lembrar são os formatos widescreen, de aspecto . Aqui temos o formato HD (1280×720), Full HD (1920×1080) e 4K (3840×2160). Vale notar que o formato 4K tem o dobro do tamanho (vertical e horizontal) do formato Full HD. Outra nota interessante é que ele não é, necessariamente “4K” (4 mil), mas tem 3840 pixels horizontais! Se bem que esses formatos geralmente são medidos pela quantidade de linhas, não de colunas. Seria esperado que o formato 4K fosse referenciado como 2.16K! :)
Existem padrões mais antigos também. O formato desses não seguem o aspecto , mas são mais “quadrados”. Por exemplo, existe o padrão NTSC-M (720×486), resultando num formato de aspecto , bem próximo do padrão letterbox de aspecto . Por quê 486 linhas? No formato NTSC temos dois quadros entrelaçados de 262.5 linhas, ou 525 linhas por quadro completo, mas apenas 486 são visíveis, as 39 linhas “invisíveis” são usadas no pulso de retraço vertical… No entanto, existem formatos europeus (um deles usado no Brasil também): PAL-M e SECAM. O formato PAL-M usa as mesmas 525 linhas, mas tem 480 visíveis, resultando no formato 720×480 com um aspecto de . É um aspecto um pouco mais “largo” (wide) que o letterbox. O padrão SECAM tem mais linhas que o NTSC-M e PAL-M (625 linhas), mas, até onde sei, não é mais usado.
Até aqui temos os formatos disponibilizados para TVs. No entanto, existem diversos formatos para vídeos em outras mídias, como cinema, por exemplo. Na telona o aspecto mais usado é de e IMAX usa os aspectos de ou , dependendo do filme. Isso não significa que não existam outros aspectos em uso. Filmes chamados de “35 mm” costumam ter aspecto de , ou seja, são duas vezes mais largos que a altura; “Super 16 mm”, por outro lado, usam ; Enquanto “70 mm” usam ; TVs antigas e alguns monitores tinham aspecto de ; Alguns distribuidores de filmes usam o aspecto de para facilitar o escalonamento para os aspectos widescreen e letterbox; Alguns monitores atuais têm aspecto de ; O padrão norte-americano para a telona de cinema costuma seguir o aspecto de … É um pesadelo, não? Não tenho como citar todas os “padrões” existentes porque simplesmente não tenho a acesso a todos eles. Não citei, por exemplo, o usado em “Super 8 mm” (popular nos primórdios, especialmente pela distribuição de filmes pornográficos nesse formato!).
Assim, recomendo que você se atenha aos padrões “de fato” mais comuns, como 540p (aspecto ); 720p, 1080p e 2160p (aspecto ) e use aquele esquema de colocar barras horizontais (ou verticais, se assim for necessário), centralizando o vídeo, se o mesmo não tiver o aspecto desejado.
Ahhh… ainda existe o pesadelo da velocidade de reprodução (quadros por segundo)… mas, deixarei isso pra depois…
Eis o script final para converter vídeos “widescreen”, mesmo com resoluções malucas. Aqui, considero qualquer vídeo com aspecto maior ou igual a , ou , como “widescreen”. Note que a comparação (em is_wide()) é feita usando cálculo inteiro, não ponto flutuante:
#!/bin/bash
# v2wide <files>
if [ -z "$1" ]; then
echo -e "\e[1;33mUsage\e[m: $0 <files>"
exit 1
fi
# Qualquer vídeo com variação de aspect ratio de 16/9 - 10%
# ou superior, considero como widescreen.
is_wide() {
if [[ $(($1 * 90)) -ge $(($2 * 159)) ]]; then
return 0
fi
return 1
}
showvideoinfo() {
FR="`mediainfo --inform='Video;%FrameRate%' "$1"`"
DURATION="`mediainfo --inform='Video;%Duration/String3%' "$1"`"
SIZE="`du -h "$1" | cut -f1`"
echo -e "\e[1m'$1'\e[m (${2}x${3}, $FR fps, $DURATION, $SIZE)"
}
# Converte TODOS os vídeos passados na linha de comando.
# Aceita, inclusive "globs", como '*.mkv', por exemplo.
for i in "$@"; do
W="`mediainfo --inform='Video;%Width%' "$i"`"
H="`mediainfo --inform='Video;%Height%' "$i"`"
if ! is_wide $W $H; then
echo -e "'$i': \e[1;31mNot a widescreen video.\e[m"
continue
fi
NW=1280
NH="`bc <<< "scale=3; 1280 / ( $W / $H )" | sed -E 's/\..+$//'`"
# Se o aspecto é inferior a 16/9, considera 16/9
if [ $NH -gt 720 ]; then
NH=720
fi
BARH=$(( ( 720 - $NH ) / 2 ))
FR='ntsc-film' # Video framerate
VBR="`bc <<< 'scale=3;(1280*720*(24000/1001))/13.824' | sed -E 's/\..+$//'`" # Video bitrate
ABR='128k' # Audio bitrate
ASR='44.1k' # Audio sampling rate
# Cria um arquivo temporário em /tmp/
TMPFILE="`mktemp /tmp/XXXXXXXXX.mp4`"
# Mostra infos do arquivo original (aproveira width
# e height já obtidos).
showvideoinfo "$i" $W $H
# Usando NVIDIA NENC para h264.
#
# Mude o codec para h265_nvenc para h265 (duh!).
#
# Note que sua placa pode codificar, no máximo, dois
# vídeos simultâneos usando NVENC (a maioria das
# low-end NVIDIA têm esse limite a não ser a Quadro e
# Titan - que podem codificar 30, acho).
#
# Aqui, uso a aceleração CUDA (cuvid) e o encoder da NVIDIA
# (h264_nvenc);
#
# Uma sincronização adaptativa de frames baseada no "novo"
# framerate (vsync 1);
#
# Formato de subsampling de chroma YUV 4:2:0 progressivo;
#
# Codec de áudio AC3 (mude para fdk AAC se quiser);
#
# Downsampling para stereo (ac 2);
#
# Sampling rate de 44.1 kHz;
#
# Resincronização de áudio com vídeo (porque o framerate
# pode ter mudado e a sincronização (vsync) pode "comer"
# frames, mudando as marcas de temporização.
#
# Eliminação de metadados e informação de "capítulos"
# (se houverem).
#
# -y (assume yes), -v error (só mostra erros se houverem),
# mostra apenas a estatística da codificação (-stats).
#
# Repare que o arquivo original é apagado e substituído por um
# de mesmo nome, mas com extensão .mp4. Em caso de falha,
# o arquivo temporário é apagado.
ffmpeg -y \
-v error \
-stats \
-hwaccel cuvid \
-i "$i" \
-c:v h264_nvenc \
-r $FR \
-bufsize $VBR \
-minrate $VBR \
-maxrate $VBR \
-b:v $VBR \
-vsync 1 \
-pix_fmt yuv420p \
-vf scale=$NW:$NH:lanczos,pad=1280:720:0:$BARH:black,setdar=16/9 \
-c:a ac3 \
-b:a $ABR \
-ac 2 \
-ar $ASR \
-async 1 \
-map_metadata -1 \
-map_chapters -1 \
"$TMPFILE" && \
( rm "$i"; mv "$TMPFILE" "${i%.*}.mp4" ) || \
rm "$TMPFILE"
done
Existem alguns meios de “juntar” dois ou mais vídeos num só. O ffmpeg possui um filtro para isso, um muxer e até um protocolo. São 3 métodos diferentes de fazer a mágica, mas a minha preferida é converter os vídeos em um formato headless, juntar os arquivos manualmente e depois recodificá-lo.
O jeito que consome menos espaço em disco, e é mais rápido, é converter os vídeos para o formato mpeg2 (container e codecs – de vídeo e áudio). Esse formato é headless, ao contrário do que temos no container mpeg4, como pode ser visto abaixo:
MPEG-4 vs MPEG-2
Repare que o container MPEG-4 possui um header cheio de metadados (que podem ser retirados), mas o MPEG-2, não! Embora o formato MPEG-2 não tenha um header, as infos dos streams estão disponíveis. Como o arquivo MPEG-2 é comprimido também, ele não consumirá muito disco, mas você terá uma pequeníssima degradação da imagem ao converter os vídeos originais para MPEG-2, juntá-los e depois reconverter tudo de volta para MPEG-4 ou usando outro par de container/codecs quaisquer.
De qualquer maneira, para juntar dois vídeos basta ter certeza que estejam com a mesma resolução, mesmo frame rate (e o mesmo sampling rate do áudio também)… Como exemplo, suponha que tenhamos um video1.mkv e um video2.avi e eu queira juntá-los. Suponha que ambos tenham resolução wide screen, mas o primeiro seja 1920×1080 e o segundo 1280×720. Suponha, ainda, que eu queira um vídeo final em 1280×720:
Os primeiros dois comandos ffmpeg convertem os vídeos para MPEG-2, garantindo a resolução de 1280×720 e o frame rate de 23.976 fps. Informei o bitrate do vídeo ligeiramente maior que o necessário para não perder qualidade (o ffmpeg usa bitrate de 200 kb/s de vídeo e 192 kb/s de áudio por default!). Repare, ainda, que não forneci os codecs de vídeo e áudio para os arquivos MPEG-2. O ffmpeg usa os defaults (mpeg2video e mp2).
Obtidos os vídeos video1.mpg e video2.mpg, é uma questão de concatená-los via comando cat e recodificar o resultado para o formato desejado. Neste caso, usando os codecs libx264 (h264) e AC-3, para um container MPEG-4.
Podemos evitar o problema de dupla degradação da imagem, por recompressões sucessivas, obtendo as características dos vídeos e convertendo-os para um formato não comprimido (RAW), mas, ainda assim, headless. Primeiro, converto os vídeos para um formato RAW com frame rate e formato de chroma subsampling conhecidos, respectivamente ntsc-film (23.976 fps) e YUV 4:2:0p, e também na mesma resolução (1280×720). Mais ou menos como fizemos antes:
Note que o bitrate é supérfluo, já que estamos convertendo para um formato RAW. Um aviso: Prepare-se! Os vídeos *.yuv, por não serem comprimidos, ocuparão um espaço enorme em disco. Para dar uma ideia, um vídeo de uns 30 minutos, por exemplo, pode chegar a ocupar uns 100 GiB! (Yep! GibiBytes!) Esse é o preço que se paga para tentar manter a qualidade…
Os “containers” *.yuv não permitem múltiplos streams. Trata-se de um arquivo com um monte de bytes, sem nenhum metadado sobre o seu conteúdo. Assim, temos que extrair os áudios, com o mesmo sample rate e quantidade de canais, mas no formato PCM (aqui usei 32 bits, little endian, sinalizado). Os áudios também não são comprimidos e, portanto, temos menos perdas, mas bastante espaço em disco usado:
O ffmpeg obedece a ordem das opções fornecidas. Antes da inclusão do arquivo de vídeo temos que dizer que ele é rawvideo e o seu formato (as opções -f, -pix_fmt, -s e -r, antes da opção -i). Depois, temos que fazer o mesmo para o áudio. Depois da inclusão dos arquivos as opções se aplicam à saída. Note que usei as opções -map para dizer que ambas as entradas têm que ser usadas na saída.
Por fim, matamos os arquivos temporários (que, provavelmente, estarão consumindo o seu disco todo, se houver espaço).
Recomendo usar alguma variação disso apenas se você quer manter a qualidade… Uma dica para a saída é não usar as opções -maxrate, -bufsize e -b:v, mas sim a opção -qp 1, que te dará a máxima qualidade possível (mas um arquivo grande), se qualidade é realmente importante no arquivo final. No que se refere ao áudio, aumente o bitrate, se necessário (192 kb/s é mais que suficiente!).
Até o momento eu estava recodificando vídeos com um frame rate de fps (ou 29.97 fps), ou seja, padrão NTSC. Com isso, segundo minha “formuletinha”, que mostrei aqui, para resolução HD, ou 720p, tería um bit rate de 1.998 Mb/s.
Mas… Que tal usar um frame rate e um bit rate menores? O menor frame rate padronizado é o NTSC-FILM ( fps, ou 23.976 fps. Isso nos dá um bit rate, para 1280×720, de 1.599 Mb/s… Esses cerca de 400 kb/s a menos nos dá uma redução de cerca de duas vezes o tamanho do stream de vídeo. Se, usando minha “formuletinha” eu conseguia uma redução de 4 a 6 vezes do tamanho do stream, agora tenho uma redução de 6 a 8 vezes!
E não… com a redução do frame rate você não tem uma degradação do vídeo. Pelo menos, não uma que você possa perceber (a não ser que você venha de Krypton, seja o Flash ou tenha os poderes de percepção de um pombo ou uma mosca!).
Considere que tenhamos um vídeo “videoin.mp4” com resolução de 1920×1080 @ 30 fps, 4.5 Mb/s… Querendo reduzir isso significativamente, eu faço:
Sempre achei que o símbolo CHAR_BIT, definido em limits.h, fosse apenas o tamanho, em bits, do tipo char. Well… estava enganado. A sessão 6.2.6.1.4 da ISO 9989:1999 (em diante) nos diz que:
“Values stored in non-bit-field objects of any other object type consist of n × CHAR_BIT bits, where n is the size of an object of that type, in bytes. The value may be copied into an object of type unsigned char [n] (e.g., by memcpy); the resulting set of bytes is called the object representation of the value. Values stored in bit-fields consist of m bits, where m is the size specified for the bit-field. The object representation is the set of m bits the bit-field comprises in the addressable storage unit holding it. Tw o values (other than NaNs) with the same object representation compare equal, but values that compare equal may have different object representations.”
Note a frase inicial: “Valores armazenados em objetos não bit-field de qualquer objeto consistem em n*CHAR_BIT bits”.
Isso é interessante, já que, em arquiteturas antigas, 1 “byte” podia ter tamanho diferente de 8 bits.
Assim como a nVidia, processadores Intel também tem suporte a codificação/decodificação de streams MPEG, especificamente ao codec AVC1 (ou h264). Mas o uso não é tão direto assim.
Em primeiro lugar, ao invés de usar o decoder cuvid, devemos usar a vaapi e, para isso, devemos instalar a biblioteca libva1 (e possivelmente a libva2). É provável que você também tenha que instalar o pacote i965-va-driver:
$ sudo apt install libva1 libva2 i965-va-driver
Agora o ffmpeg pode usar a VAAPI e, para isso devemos usar o decoder vaapi como em -hwaccel vaapi, mas também temos que informar qual é o device que queremos. Geralmente esse device é o /dev/dri/renderD128:
$ ls -l /dev/dri
total 0
drwxr-xr-x 2 root root 80 jan 9 08:21 by-path
crw-rw----+ 1 root video 226, 0 jan 9 08:21 card0
crw-rw----+ 1 root video 226, 128 jan 9 08:21 renderD128
Agora, o encoder h264_vaapi pode ser usado, mas, precisa acrescentar um filtro final (se usarmos algum filtro de vídeo): hwupload. Isso fará com que cada quadro seja repassado para o codec para ser processado em hardware.
Note que hwupload vai enviar o quadro depois que ele foi escalonado (e depois que qualquer outro filtro antes da codificação).
Sem a opção -vaapi_device (ou -haccel_device, que acredito que funcionará do mesmo jeito) e sem o filtro final hwupload, a codificação usando h264_vaapinão funcionará.
Outro detalhe importante (pelo menos onte pude testar) é que o chroma subsampling YUV 4:2:0 não funciona com esse encoder (h264_vaapi) – pelo menos não num i5-3570. É possível que em gerações mais novas funcione bem… Mas o subsampling NV12 funciona. Por isso o filtro format=nv12.
Parece (e é) estranho, alguém querer gravar DVDs nesse mundo “cloudeado”. A questão me ocorreu pois tenho um monte de dvd+rw parados que iriam pro lixo.
Pendrives são bem baratos e HDs SSDs também, mas acho que é justamente isso o que me atraiu: os CDs, DVD, Blu-rays são mídias “estáticas” e chatas de gravar, portanto ao fazê-lo, a disciplina surge automaticamente: você deve pensar no que vai colocar ali, pois irá ficar “pra sempre”.
Aquela tentação imediata de apagar a mídia é mais branda, diferente da nossa abordagem com pendrives que são “limpos” na hora, só porque você deve mandar algo para alguém. E até porque “alguém” já nem deve ter mais um leitor de dvd instalado no computador… Se ainda houver um computador!
Mas, em geral, como o que faço é para meu próprio uso, me veio então a idéia (não muito original, sei): gravar dvds usando scripts e ferramentas de linha de comando com a seguinte condição:
Fazer isso no windows, porém através do Cygwin (nem pensar em .bat e nem naquela porcaria de powershell)
Levantei o set de comandos necessários e instalei:
wodim
cdrecord (front end para o wodim)
genisoimage
Notando que o Cygwin não possui, em seu conjunto de pacotes nativos, cdrtools nem dvd+rw-tools, entendi, pela necessidade, que sendo as minhas mídias – dvd+rw – precisariam ser “formatadas” antes de gravar.
Eis os passos, após instalados os pacotes acima citados, no Cygwin (ou Linux):
Criar a imagem
Criar um checksum da imagem (se for transferir)
Inserir o dvd
Gravar usando o … dd, ao invés do wodim ou cdrecord
Uma das coisas que os amantes de C++ e de linguagens gerenciadas mais gostam é a “limpeza automática” que códigos escritos nessas linguagens parecem fazer. No caso de C++, objetos alocados na pilha são “destruídos” quando há perda do escopo da função. No caso de C# e Java, por exemplo, quando o objeto não é referenciado por nenhum outro, o Garbage Collector tende a livrar-se dele. Em C, aparentemente, não temos esse benefício:
void f( void )
{
char *bufferp;
...
bufferp = malloc( SIZE );
...
// MEMORY LEAK: O buffer alocado não foi liberado!
}
Nada tema! GCC tem a solução!
Existe um atributo para variáveis que pode ser usado para fazer esse tipo de liberação automática. Tudo o que temos que fazer é criar a função de liberação a atrelá-la à variável:
Graças a esse atributo, a função cleanup_func é chamada, com o argumento correto, sempre que a variável sai do escopo. Isso significa que não só quando a função termina, mas em casos como esse:
Para não ter que ficar codificando uma função de cleanup (que sempre recebe um ponteiro para um ponteiro), podemos usar a glib e a macro g_autofree:
g_autofree char *bufferp;
É claro, é prudente inicializar o ponteiro com NULL para o caso de nenhuma alocação ter sido feita… A especificação da linguagem C, ISO 9989, nos diz que se passarmos NULL para free, este simplesmente não faz nada (não causa segmentation fault).
ATENÇÃO! O atributo exige que o tipo informado seja um ponteiro para o ponteiro do mesmo tipo. No entanto, (void **) apontará para qualquer tipo e não haverá problema algum, mas o compilador emitirá avisos…
 (4×4, 8×8, 16×16 ou, no caso do h265, outros tamanhos múltiplos de
(4×4, 8×8, 16×16 ou, no caso do h265, outros tamanhos múltiplos de  . Aqui temos o formato HD (1280×720), Full HD (1920×1080) e 4K (3840×2160). Vale notar que o formato 4K tem o dobro do tamanho (vertical e horizontal) do formato Full HD. Outra nota interessante é que ele não é, necessariamente “4K” (4 mil), mas tem 3840 pixels horizontais! Se bem que esses formatos geralmente são medidos pela quantidade de linhas, não de colunas. Seria esperado que o formato 4K fosse referenciado como 2.16K! :)
. Aqui temos o formato HD (1280×720), Full HD (1920×1080) e 4K (3840×2160). Vale notar que o formato 4K tem o dobro do tamanho (vertical e horizontal) do formato Full HD. Outra nota interessante é que ele não é, necessariamente “4K” (4 mil), mas tem 3840 pixels horizontais! Se bem que esses formatos geralmente são medidos pela quantidade de linhas, não de colunas. Seria esperado que o formato 4K fosse referenciado como 2.16K! :) , bem próximo do padrão letterbox de aspecto
, bem próximo do padrão letterbox de aspecto  . Por quê 486 linhas? No formato NTSC temos dois quadros entrelaçados de 262.5 linhas, ou 525 linhas por quadro completo, mas apenas 486 são visíveis, as 39 linhas “invisíveis” são usadas no pulso de retraço vertical… No entanto, existem formatos europeus (um deles usado no Brasil também): PAL-M e SECAM. O formato PAL-M usa as mesmas 525 linhas, mas tem 480 visíveis, resultando no formato 720×480 com um aspecto de
. Por quê 486 linhas? No formato NTSC temos dois quadros entrelaçados de 262.5 linhas, ou 525 linhas por quadro completo, mas apenas 486 são visíveis, as 39 linhas “invisíveis” são usadas no pulso de retraço vertical… No entanto, existem formatos europeus (um deles usado no Brasil também): PAL-M e SECAM. O formato PAL-M usa as mesmas 525 linhas, mas tem 480 visíveis, resultando no formato 720×480 com um aspecto de  . É um aspecto um pouco mais “largo” (wide) que o letterbox. O padrão SECAM tem mais linhas que o NTSC-M e PAL-M (625 linhas), mas, até onde sei, não é mais usado.
. É um aspecto um pouco mais “largo” (wide) que o letterbox. O padrão SECAM tem mais linhas que o NTSC-M e PAL-M (625 linhas), mas, até onde sei, não é mais usado. e IMAX usa os aspectos de
e IMAX usa os aspectos de  ou
ou  , dependendo do filme. Isso não significa que não existam outros aspectos em uso. Filmes chamados de “35 mm” costumam ter aspecto de
, dependendo do filme. Isso não significa que não existam outros aspectos em uso. Filmes chamados de “35 mm” costumam ter aspecto de 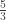 ; Enquanto “70 mm” usam
; Enquanto “70 mm” usam  ; TVs antigas e alguns monitores tinham aspecto de
; TVs antigas e alguns monitores tinham aspecto de  ; Alguns distribuidores de filmes usam o aspecto de
; Alguns distribuidores de filmes usam o aspecto de  para facilitar o escalonamento para os aspectos widescreen e letterbox; Alguns monitores atuais têm aspecto de
para facilitar o escalonamento para os aspectos widescreen e letterbox; Alguns monitores atuais têm aspecto de 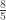 ; O padrão norte-americano para a telona de cinema costuma seguir o aspecto de
; O padrão norte-americano para a telona de cinema costuma seguir o aspecto de  … É um pesadelo, não? Não tenho como citar todas os “padrões” existentes porque simplesmente não tenho a acesso a todos eles. Não citei, por exemplo, o usado em “Super 8 mm” (popular nos primórdios, especialmente pela distribuição de filmes pornográficos nesse formato!).
… É um pesadelo, não? Não tenho como citar todas os “padrões” existentes porque simplesmente não tenho a acesso a todos eles. Não citei, por exemplo, o usado em “Super 8 mm” (popular nos primórdios, especialmente pela distribuição de filmes pornográficos nesse formato!). , ou
, ou  , como “widescreen”. Note que a comparação (em is_wide()) é feita usando cálculo inteiro, não ponto flutuante:
, como “widescreen”. Note que a comparação (em is_wide()) é feita usando cálculo inteiro, não ponto flutuante:
 fps (ou 29.97 fps), ou seja, padrão NTSC. Com isso, segundo minha “formuletinha”, que mostrei
fps (ou 29.97 fps), ou seja, padrão NTSC. Com isso, segundo minha “formuletinha”, que mostrei  fps, ou 23.976 fps. Isso nos dá um bit rate, para 1280×720, de 1.599 Mb/s… Esses cerca de 400 kb/s a menos nos dá uma redução de cerca de duas vezes o tamanho do stream de vídeo. Se, usando minha “formuletinha” eu conseguia uma redução de 4 a 6 vezes do tamanho do stream, agora tenho uma redução de 6 a 8 vezes!
fps, ou 23.976 fps. Isso nos dá um bit rate, para 1280×720, de 1.599 Mb/s… Esses cerca de 400 kb/s a menos nos dá uma redução de cerca de duas vezes o tamanho do stream de vídeo. Se, usando minha “formuletinha” eu conseguia uma redução de 4 a 6 vezes do tamanho do stream, agora tenho uma redução de 6 a 8 vezes!

Você precisa fazer login para comentar.