Uma querida amiga, no Facebook, mostrou-se interessada em aprender um bocado a respeito de eletrônica digital e topou com os mapas de Karnaugh, como recurso para tornar mais simples o esforço de realizar “simplificações” de expressões lógicas. Neste texto vou mostrar para vocês dois estilos diferentes de mapas, como montá-los e usá-los. Mas, antes, é importante entender como fazer esse tipo de simplificação manualmente.
Como na álgebra tradicional, a Booleana também é baseada em certas operações elementares. Para facilitar a compreensão, usarei o símbolo de adição (+) para representar a operação OR e multiplicações para representar AND. Assim, a expressão será a mesma coisa que .
A primeira propriedade é a de identidade. Ou seja, e . Outra propriedade interessante é a que acontece quando invertemos o valor fixado para as operações OR e AND: e . Com essas quatro proriedade fica fácil de ver que: , por exemplo… Também temos a propriedade distributiva, , assim como na aritmética tradicional. O que não é muito evidente é que AND também pode ser distribuído: , e vice-versa, se colocarmos A “em evidência”.
Vejamos como isso funciona com uma expressão do tipo : Pela propriedade distributiva podemos reescrever a expressão como . Se e, ao mesmo tempo, . O que nos dá: , ou seja, eliminamos o da expressão.
Acontece que esse tipo de simplificação pode ser bem complicada para fazer “de cabeça”. E podemos nos confundir se podemos (ou se devemos) realizar uma distribuição usando AND ou OR. Para isso existem os mapas de Karnaugh.
Simplificação com mapa de Karnaugh
Como funciona esse mapa? Trata-se de um retângulo onde, nas colunas, temos as representações de A e seu inverso (1 e 0, ou vice-versa) e nas linhas, B e seu inverso. Uma expressão a ser simplificada deve ser interpretada como sendo constituída de “somas” de produtos… No caso da expressão , o isolado deve ser transformado para e assim, obtemos a equação final . Daí, em cada termo das “adições” colocamos, no mapa, o valor 1.
Agora precisamos “agrupar” esses uns de acordo com as seguintes regras:
Apenas “uns” adjacentes podem formar grupos (“uns” diagonais não!);
Apenas grupos de “uns” podem ser formados. Ou seja, cada grupo pode ser formado por 1, 2, 4, 8, 16… “uns”;
Apenas grupos “linhas”, “quadrados” ou “retângulos” podem ser formados (veremos isso com mapas com 3 ou mais variáveis);
Devemos sempre começar pelos maiores grupos possíveis;
Podemos compartilhar “uns” de grupos que já tenham sido formados, desde que pelo menos 1 deles não faça parte de outros grupos;
Se não há mais “uns” fora de grupos já formados, novos grupos não devem ser formados;
A menor quantidade possível de grupos deve ser formada.
Com essas regras obteremos a equação final com a menor quantidade de termos (regra 7) com menores termos (especialmente a regra 4).
No exemplo acima tivemos que formar 2 grupos com 2 “uns” (o verde e o avermelhado) porquê não pudemos criar nenhum grupo com 4 “uns”.
Para cada grupo verificamos quais variáveis não possuem complementos e as escrevemos como um produto… No caso, o grupo vermelho é composto de , mas têm e , portanto ambos são eliminados, ficando apenas … A mesma coisa se dá com o grupo verde, ficando apenas .
Note que, no mapa com duas variáveis, se tivéssemos uma expressão do tipo , todos as 4 posições teriam “uns” e o resultado final serial … Isso nos dá uma regra interessante:
Grupos com “uns” eliminam variáveis.
Um grupo grande com 4 “uns” eliminará, necessariamente, 2 variáveis da expressão. No caso anterior, como a expressão só tem duas variáveis, o resultado só pode ser 1. Isso ficará claro, adiante, com mapas maiores.
Mapas de 3 ou 4 variáveis
A diferença de um mapa com mais de duas variáveis é que ele pode se “fechar” lateralmente. No mapa abaixo, para colocarmos mais uma variável, decidi particionar as colunas e em duas, mas note que para que a porção fique completa, os lados direito e esquerdo do mapa precisam “se tocar”. Ou seja, o mapa deixou de ser plano para ser cilíndrico.
Exemplo com 3 variáveis
No exemplo acima, temos que começar com um grupo de 4 “uns” (o avermelhado). Note que os “uns” continuam adjacentes, mas não formam uma linha. Formam um “quadrado”… Com isso fica “sobrando” um “1” no mapa que, infelizmente, não pode formar nenhum outro grupo de 4, restando apenas uma possibilidade: um grupo de 2 “uns”, usando um já usado no grupo anterior.
O grupo de 4 “uns” elimina duas das três variáveis. Se prestarmos atenção o grupo usa , , e , mas usa apenas … O grupo de dois “uns” elimina uma única variável, permanecendo apenas .
Um mapa de 4 variáveis faz e mesma coisa que o mapa de 3, mas ele dividirá as linhas de e , da mesma forma que fiz com e , mas do lado direito no mapa… Assim, ele se fechará nos dois sentidos, formando uma “toroide” (um cilindro fechado dos dois lados… ou um “pneu”):
Mapa com 4 variáveis
Mapas com mais de 4 variáveis e a codificação de Gray
Mapas com mais de 4 variáveis podem ser montados de acordo com o esquema anterior, porém em 3D. Eu acho particularmente difícil conceber tais mapas tridimensionais e, portanto, para continuar usando Karnaugh, um outro esquema, mais tradicional, é necessário. O mapa pode ser montado de forma bidimensional onde cada linha ou coluna varie, entre uma e outra, em apenas 1 bit, como mostrado abaixo:
Esse tipo de mapa tem que usar uma codificação para cada linha/coluna chamada de código de Gray, já que, assim como mapa de 4 variáveis, ele se “fecha” nos dois sentidos… Isso fica meio chato de montar, mas o código de Gray pode ser obtido para n bits assim:
Começamos pelos dois primeiros valores: 0 e 1. Os dois próximos são os mesmos dois primeiros, porém revertidos, com o próximo bit setado. Ou seja, se temos 0 e 1, obtemos 11 e 10 e teremos a sequência {00,01,11,10}. A próxima sequência é essa mesma, revertida, com o próximo bit setado, ou seja, {110,111,101,100}, o que nos dá a sequência completa {000,001,011,010,110,111,101,100}, para 3 bits… Esse mesmo algoritmo pode ser usado para n bits…
No que concerne o uso do mapa, você coloca os “uns” em cada uma das posições dos produtos, onde 0 significa a variável “negada”, e segue as mesmas regras anteriores (grupos grandes, poucos grupos e grupos de “uns”). A chatice é determinar quais das variáveis não sofreram alterações nos grupos… Suponha que tenhamos um grupo de 8 “uns” e verificamos que apenas A e B não sofreram variações (A=0 e B=1, no grupo todo, por exemplo)… Assim, para esse grupo de 8 “uns” (e, por causa disso 3 variáveis serão eliminadas, necessariamente, já que ), obteremos .
Desse jeito podemos montar mapas de qualquer tamanho. Mas, atenção que apenas 4 bits nos darão uma linha com 16 possibilidades diferentes. Um mapa com 8 bits, agrupados de 4 em 4, nos dará um mapa com 256 posições!
Usando mapas de Karnaugh com comparações, num if…then…else
Claro que usei variáveis booleanas A, B, C, … levando em conta que elas podem assumir apenas dois valores: true ou false. A mesma coisa pode ser feita com uma comparação como (x < 0), só temos que tomar cuidado com os complementos… Por exemplo, o contrário de (x < 0) é (x >= 0)… Assim, um if do tipo:
if ((x < 0) || ((x >= 0) && (a == b))) { ... }
Pode ser decrito como tendo , e . O que nos daria a expressão . Como vimos, isso pode ser simplificado para e, portanto, o if acima ficaria:
if ((x < 0) || (a == b)) { ... }
O compilador pode fazer essa simplificação para nós, mas nem sempre ele consegue.
Já falei por aqui o que é uma interrupção, certo? Acho que falei… Mas, ai vai, de novo: Uma interrupção é um sinal elétrico que é colocado num pino do processador por um circuito externo na intenção de pedir que o processador interrompa o fluxo de processamento normal e execute uma rotina de tratamento, em benefício do circuito que requisitou essa “interrupção”… Ou seja: O processador pára o que está fazendo e executa uma rotininha para satisfazer as necessidades do circuito externo.
Esse “circuito externo” pode ser qualquer coisa. Por exemplo, um HD pode pedir uma interrupção para que o processador leia um bloco de dados que ele mesmo requisitou anteriormente… A porta serial pode pedir uma interrupção para que o processador leia um byte que foi recebido… Uma placa de som pode pedir uma interrupção para informar que o buffer de dados está pronto para receber mais samples… etc.
Repare, no entanto, que o dispositivo pode pedir uma interrupção (Interrupt Request ou IRQ), mas tem que esperar que o processador a aceite (Interrupt Acknowledge). Ou seja, o processador não interrompe o processamento normal só porque o dispositivo externo quer. Só atenderá a interrupção quando o processador mesmo quiser…
Na arquitetura de processadores Intel x86, além do sinal de pedido de interrupção (Interrupt Request ou IRQ), o dispositivo requisitante tem que enviar um valor de 8 bits informando o número da interrupção que lhe convém… Em teoria, o processador pode atender a 224 interrupções diferentes (seriam 256, mas 32 delas são reservadas pela Intel). Na prática, o circuito dos PCs permite apenas 15 interrupções diferentes, numeradas de IRQ0 até IRQ15 (onde a IRQ2 é reservada, explico porquê mais adiante!).
Esse esquema de receber um pedido de interrupção (sinal INT vai para nível alto) e enviar um “aceite” (sinal INTA# vai para nível baixo!) gera uma complicação: Esses sinais não podem ser compartilhados por todos os circuitos, externos ao processador, ao mesmo tempo. Se fosse o caso, dois circuitos poderiam colocar o sinal INT em nível alto e ambos, depois de receberem o INTA#, tentariam enviar, no barramento de dados, o número da interrupção desejada… Esse é o problema enfrentado pelos projetistas de microcomputadores baseados na arquitetura Intel… Daí a necessidade de um controlador de interrupções… Um circuito integrado que coordena os pedidos e atendimentos à interrupções de vários dispositivos, mas que seja a única comunicação com o processador!
Sempre que você topar com a palavra “controlador”, assuma algum tipo de compartilhamento… Esse sujeito, assim como na vida real, é o “gerente” de vários trabalhadores (dispositivos) em benefício da empresa (processador)… Por isso temos o PIC (Programmable Interrupt Controller) e o DMAC (Direct Memory Access Controller), por exemplo… Todos os dispositivos não podem requisitar esses recursos ao mesmo tempo. Tem que haver alguém controlando quem pede o que, quando e a quem…
O PIC 8259A:
Embora as arquiteturas de PCs modernas, desde o lançamento do Pentium, possuam um controlador mais moderno, chamado de APIC (Advanced Programmable Interrupt Controller), o PIC padrão (o circuito integrado 8259A da Intel – baixe o datasheet aqui) ainda está disponível de forma emulada nesses novos controladores. O APIC está disponível em dois sabores: LAPIC e I/O APIC. O primeiro está incorporado no processador e existe um para cada processador lógico (ou para um par deles, falarei disso em outro artigo). O ‘L’ de LAPIC significa “Local”.
O I/O APIC faz o trabalho do antigo PIC e é externo ao processador.
Pra que diabos existe um LAPIC então? Well… é complicado: Mas, resumindo, algumas coisas como multitarefa simétrica precisa lidar com interrupções que não vẽm de dispositivos…
Como o PIC funciona?
O 8259A permite a coordenação de até 8 requisições de interrupções simultâneas. Ele possui 8 entradas de requisição, numeradas de IRQ0 até IRQ7 e o chip possui a lógica para lidar com os sinais INT e INTA# do processador, bem como com o barramento de dados (para enviar “qual” interrupção está sendo pedida).
Quando queremos tratar interrupções vindas de um dispositivo, tudo o que temos que fazer é escrever uma rotina de tratamento de interrupções e apontar para ela num vetor da tabela de vetores de interrupções. Depois, temos que habilitar o reconhecimento da interrupção no PIC… O primeiro passo é simples no modo real: O primeiro bloco de 1 KiB da memória contém os ponteiros “far” para cada uma das 256 rotinas de tratamento de interrupções possíveis no formato segmento:offset… A diferença dessas rotinas para as funções tradicionais de nossos códigos é que elas terminam com a instrução IRET, ao invés do simples RET.
Só por curiosidade, no velho MS-DOS, usando o Turbo C, podíamos escrever algo assim:
void interrupt (*old_isr)(void);
void interrupt isr_serial(void)
{
...
}
/* Guarda a velha ISR (Interrupt Service Routine) e
ajusta o novo... */
old_isr = getvect(11);
setvect(11, isr_serial);
...
/* Recupera a velha ISR... */
setvect(11, old_isr);
O modificador interrupt tratava de colocar um IRET no final da rotina. E as funções getvect() e setvect do MS-DOS ajustavam os ponteiros na tabela de vetores de interrupções para nós… Fique avisado: Isso não funciona mais assim nos sistemas operacionais modernos! Vale apenas lembrar que o atributo interrupt também existe para o modo protegido no GCC e tem a mesmíssima função. Somente o método de setup e o funcionamento das interrupções é que são um pouco diferentes no modo protegido.
Como estamos lidando com um controlador, temos que informá-lo quando o processador terminou a interrupção… Isso é feito enviando um comando EOI (End of Interruption) para o PIC. Mais adiante mostro como isso é feito, mas, olhando para o datasheet do 8259A você verá que existem dois tipos de EOI… Um que diz ao controlador qual é a interrupção que terminou e outro que diz “se vira ai, PIC… terminei uma interrupção”… Esse último tipo, o unspecified, é o mais comum, uma vez que, geralmente, o processador atenderá uma interrupção de cada vez… Isso não quer dizer que, em certos casos, uma interrupção não possa ser requisitada enquanto um tratador ainda não tiver terminado o seu trabalho… Só que isso não é tão comum.
Depois ajustado o ponteiro para o tratador de interrupção temos que configurar a correspondente IRQ com o número do vetor, no PIC. Geralmente isso é feito pela BIOS: A IRQ0, por exemplo, está associada ao vetor 8, a IRQ1 ao 9 e assim por diante… Nada nos impede de mudar essa sequencia, mas eu não aconselho fazê-lo.
Uma vez que o vetor esteja configurado, precisamos habilitar o tratamento da interrupção no PIC. Isso é feito por um registrador de “máscara”… A analogia da “máscara” aqui é a de que uma interrupção pode ser “escondida” do processador e jamais ser requisitada através do PIC. Esse registrador tem 8 bits, um para cada IRQ. Se o bit estiver setado a interrupção estará “mascarada” (não será tratada), se for 0, a máscara é retirada e, se o sinal IRQ correspondente sinalizar a requisição, o PIC a repassará para o processador.
Os sinais IRQ:
A maioria dos dispositivos sinaliza seu desejo por uma requisição na subida do pulso do sinal IRQ… É o que você pode ler na documentação sobre o PIC e os APICs, chamada de edge assertion. Mas, podem existir casos que o sinal IRQ é sinalizado durante todo o tempo em que permanecer em nível alto (isso é raro, na arquitetura do PC). É o que é chamado de level assertion.
Os registradores IRR e ISR:
Esses são dois registradores de status do PIC que informam quais interrupções foram requisitadas (IRR de Interrupts Requested Register) e quais estão “em serviço” (ISR de In Service Register). As interrupções “em serviço” são aquelas que ainda não receberam o EOI… Por isso o envio do EOI, por parte do processado, é importante… O PIC só aceitará outra interrupção do mesmo dispositivo depois se ela não estiver “em serviço”…
Pera ai… mas o PC aceita 15 interrupções!!
Pois é… O PIC consegue tratar apenas 8. Então, como as outras 7 se encaixam nisso? Acontece que o PIC 8259A é feito para trabalhar, se necessário, “em cascata”. Ou seja, existe um PIC mestre e podem existir PICs escravos. Um PIC escravo pode atender um conjunto de IRQs e repassá-las para o mestre. Somente o mestre tem acesso ao processador.
No caso do PC temos dois 8259A. O primeiro trata diretamente as IRQs de 0 até 7, exceto a IRQ2, que é “cascateada” para o PIC escravo, que tratará as IRQs 8 até 15.
Assim, a IRQ2 é inutilizada… No caso do PC a prioridade das IRQs passa a ser: IRQ0, IRQ1, IRQ8 até IRQ15, IRQ3, IRQ4, … IRQ7. A lista abaixo mostra quais dispositivos estão ligados a cada uma dessas IRQs, no PC:
IRQ0 – Timer (PIT)
IRQ1 – Teclado (KBDC)
IRQ2 – cascateada para o PIC2 (indisponível para dispositovos)
IRQ3 – Serial 2 (COM2 no velho DOS)
IRQ4 – Serial 1 (COM1 no velho DOS)
IRQ5 – Porta paralela 2 ou placa de som (SoundBlaster)
IRQ6 – Diskette (FDC)
IRQ7 – Porta paralela 1 ou placa de som (SoundBlaster)
IRQ8 – Relógio de tempo real (RTC)
IRQ9 – ACPI
IRQ10 – livre (algumas controladoras SCSI usam)
IRQ11 – livre (algumas controladoras SCSI usam)
IRQ12 – mouse
IRQ13 – Coprocessador 8087 (quando existia)
IRQ14 – HDC 1
IRQ15 – HDC 2
Repare que, na sequencia das prioridades, a interrupção do RTC é atendido antes da do diskette, por exemplo, graças ao esquema de cascateamento dos PICs.
A confusa sequência de inicialização e operação do PIC:
Infelizmente, lidar com o PIC não é a tarefa trivial de ajustar valores em registradores e deixar o “pau quebrar”. A inicialização e operação do 8259A é feita de forma sequencial, com comandos enviados um depois do outro, numa sequencia correta. Existem dois grupos de sequências possíveis: ICWs de Initialization Command Words e OCWs de Operation Control Words.
Na sequência de inicialização, dois bytes são obrigatórios, chamados de ICW1 e ICW2. O byte ICW1 diz, entre outras coisas, se o PIC tem um escravo e se o vetor de interrupção trata IRQ sinalizada por edge ou level. O byte ICW2 informa o vetor da IRQ.
No caso do PC, como temos um PIC escravo, a palavra ICW3 é obrigatória também, assim como a ICW4… Deixo os detalhes de como configurar esses 4 bytes para leitura que você fará do datasheet, mas o importante é saber que sempre que for necessária uma inicialização do PIC, 4 bytes têm que ser escritos em sequência!
Nos PCs as OCWs são mais simples… a OCW1 é a máscara das interrupções do PIC. A OCW2 é mais usada para receber o EOI.
A diferença do velho MSDOS e os sistemas modernos:
Além de termos que lidar com o APIC (noutro texto falo disso), o modo protegido impõe várias outras coisinhas… Por exemplo: Não existe mais uma tabela de vetores de interrupções centralizada onde só precisamos informar os ponteiros para as rotinas de tratamento… Agora temos uma tabela de descritores de interrupções (IDT, Interrupt Descriptor Table) e cada entrada pode conter um de três “tipos” de interrupções diferentes: Task, Interrput ou Trap gates (consulte o volume 3 dos manuais de desenvolvimento da Intel)… Ainda, cada uma das entradas possui um nível de privilégio (geralmente para o ring 0).
Outra complicação é que as entradas na IDT contém seletor para onde o processador saltará… Em essência, é como se cada entrada contivesse o par segmento:offset da antiga tabela de vetores, mas seletor tem que estar descrito na tabela de descritores globais ou locais (GDT ou LDT)… que também têm lá suas características de proteção…
Circuitos lógicos são simples: Não passam um monte de portas lógicas (AND, OR, NOT ou XOR) ligadas de maneira a obedecerem uma equação lógica… Neste texto eu não vou explicar o funcionamento de uma porta lógica e sequer como montar ou simplificar uma equação lógica. O que nos interessa é uma classe de circuitos lógicos chamados flip-flops.
Um flip-flop pode ser entendido como sendo uma espécie de “memória” de apenas um bit. Ele armazena um estado lógico e o mantém estável até que este estado seja modificado. No jargão da eletrônica analógica eles são conhecidos como mutivibradores biestáveis (porque podem assumir dois estados estáveis: 0 ou 1). Na eletrônica digital receberam esse ridículo nome, suspeito eu, porque na gíria, em inglês, pessoas que mudam de ideia facilmente são “flip-floppers” (a alternativa é usar a gíria para “chinelo”, que também é “flip-flop”!).
Do ponto de vista do desenvolvedor de software apenas um dos tipos de flip-flops é interessante: O flip-flop tipo D:
Aqui tenos duas entradas (D e E, de Data e Enable, respectivamente) e duas saídas (Q e Q#). Na realidade, podemos considerar as saídas como uma só: Q. O sinal Q# é apenas o complemento do outro… Esse cara ai em cima funciona assim: Quando a entrada E (pode-se achar essa entrada nomeada como T de Trigger ou “gatilho”, na literatura técnica) estiver setada (1), a saída Q será colocada no mesmo valor da entrada D. Mas, quanto a entrada E estiver zerada, a saída Q não se altera, seja qual for o valor em D. Ou seja, se E for zero, o último estado de D (quanto E era 1) terá sido armazenado.
Note que a saída depende do nível de E. Enquanto E estiver em nível alto, a saída Q será uma cópia da entrada D. Apenas quando E for zerada é que a última entrada D estará “armazenada”. A maioria dos circuitos lógicos micro-processados não funciona assim. Neles, o armazenamento é feito de uma maneira mais rápida, no pequeno período de transição entre um nível e outro do sinal de E. Ou, se preferir, no “canto” (edge) do pulso de “clock”. Abaixo mostro como um flip-flop D com gatilho na descida do pulso de clock funciona.
Quem disse que escravidão era uma coisa ruim?
O circuito lógico abaixo faz a mágica do armazenamento na transição da “descida do pulso de clock”:
Se você reparar bem, existem dois flip-flops neste circuito: As duas portas AND e as duas portas NOR, à esquerda, formam um flip-flop mestre do tipo D e as mesmas portas, à direita, formam um flip flopescravo (do tipo RST, mas isso não é importante aqui!).
A ideia aqui é que o flip-flop mestre altera o estado de suas saídas quando o sinal CLK estiver em nível alto. Essas saídas são os pontos na saída das portas lógicas NOR, mais à esquerda… Para esse flip-flop o sinal CLK funciona do mesmo jeito que o sinal E citado anteriormente. Repare que, quanto CLK for 1, a porta inversora ligada a ele colocará um valor zero nas portas AND mais à direita. Ou seja, o sinal Edo flip-flop escravo será zero.
Quando o sinal de CLK pular do nível alto para o baixo, o flip-flop mestre estabilizará sua saída de acordo com o último valor em D, da mesma maneira que citei lá em cima… Mas, o flip-flop escravo mudará a saída Q de acordo com suas entradas (ou as saídas do mestre). Até aqui nada ficou muito diferente do flip-flop D comum, mas observe que quanto CLK “sobe” (passa de 0 para 1) o flip-flop escravo terá sua saída estabilizada e o flip-flop mestre, agora, terá sua saída “desestabilizada”. Isso quer dizer que, de maneira global, o flip-flop só alterará a saída Q na descida do pulso de clock, mantendo-o estável no resto do tempo!
O flip-flop, acima, continua sendo um tipo D e é simbolizado, num diagrama de blocos, como abaixo:
Repare no pequeno triângulo e na inversão do sinal CK… O triângulo diz “transição de clock” e a “bolinha” diz “descida”… Sem a “bolinha” o flip-flop funcionaria na “subida do pulso”…
Memória RAM não funciona assim!!!
Você poderia ficar tentado a acreditar que a memória RAM do seu PC funciona dessa maneira. Nah! Não é bem assim…
Repare que precisamos de 10 portas lógicas para o armazenamento de apenas 1 bit, usando um único flip-flop tipo D. Num PC atual, com uns 8 GiB de RAM, precisaríamos de uns 68 bilhões de flip-flops tipo D, com 10 portas lógicas cada um e, com cada porta com uns 8 transístores (em média), ou seja, apenas para a memória do sistema teríamos 5,5 trilhões de transístores… O circuito ficaria enorme e caro.
De fato, existe um tipo de RAM que funciona à base de flip-flops tipo D, chamada memória RAM estática (SRAM de Static RAM). Mas, a RAM do seu PC é dinâmica (DRAM de Dynamic RAM) e os bits armazenados correspondem à carga de pequeníssimos capacitores:
O esquema acima, é claro, é simplificado. Essencialmente temos que fornecer o “endereço” da linha e da coluna onde um capacitor se encontra numa matriz. Ele é carregado (escrita) ou “lido” através de um pequeno transístor… Infelizmente a carga destes capacitores rapidamente decaem e ai é que entra o processo de “refrescamento”. As memórias RAM dinâmicas precisam ser relembradas o tempo todo e elas funcionam assim desde sua criação, em 1968 (invenção da IBM).
Embora o circuito seja mais simples e há a desvantagem da lentidão (carga e descarga controlada de capacitores implicam em “constantes de tempo”) ele é bem mais barato e fácil de ser construído. Dando uma olhada na topografia de um DIE de uma DRAM genérica, vemos algo mais ou menos assim:
Essas áreas cinzentas, no meio do DIE, são aqueles pequenos FETs e capacitores. O resto do circuito correspondem à decodificação das linhas e colunas, bem como o condicionamento do sinais para leitura/escrita/refresh.
Compare agora o die acima, com um die da arquitetura Haswell-E, de 22 nm:
Tenha em mente que a densidade (ou, se preferir, o “tamanho”) dos transístores, diodos, capacitores, resistores etc, é muito maior do que numa simples DRAM… Por exemplo, essa área central, com aqueles montes de “ilhas” retangulares de aspecto claro, é o cache L3 (20 MiB no i7-5960X), mas os outros caches não são facilmente identificáveis (estão, provavelmente do lado direito — naquela região rosada — e não são aquelas áreas verdes!). Abaixo e acima do cache L3 estão os 8 “cores” (cada um com 2 processadores lógicos) e, à esquerda do DIE, temos os circuitos de I/O.
O ponto aqui é que o processador não usa DRAM dentro de si, mesmo porque o tamanho dos capacitores teria que ser grande para conseguirem manter carga por tempo suficiente, o que aumentaria o tamanho do DIE consideravelmente… Assim, memória dentro de um processador tem que ser implementada como SRAM (Static RAM), ou seja, com flip-flops.
Externamente ao processador os flip-flops também são úteis como pequenas memórias. É o caso dos latches…
Fechando a abrindo o trinco…
Um latch (trinco ou tranca, em inglês) nada mais é do que um conjunto de flip-flops tipo D com o pino E ou CLK em comum (dependendo se a trava acontece por nível ou transição de clock). As placas VGA, por exemplo, possuem latches que armazenam valores lidos da memória de vídeo (um latch de 8 bits para cada “plano”) e são usados para evitar acessos espúrios à memória de vídeo (quando alteramos um byte e o circuito estiver desenhando-o na tela)…Também são usados como memória temporária para operações de raster (ROP = Raster OPeration. Aliás, “raster” é um substantivo: “a rectangular pattern of parallel scanning lines followed by the electron beam on a television screen or computer monitor”), como, por exemplo, ao escrevermos um dado na memória de vídeo, uma operação lógica pode ser feita com o conteúdo de um ou mais latches — escreví sobre isso em meu velho curso de assembly…
Outro uso para latches é visto no circuito que decodifica endereços de memória vindos do processador… É comum (em processadores Intel) que o mesmo barramento seja usado para fornecer/receber endereços e para ler/escrever dados. O endereço é fornecido primeiro e “armazenado” em um latch. Depois que isso é feito, os dados serão lidos/gravados e o endereço será obtido do latch, pelo circuito de controle das memórias.
Esses trincos são, então, pequenas memórias que armazenam uma quantidade limitada de bits (8, 16, 24, 32, …). E latches são, óbviamente, muito maisrápidos que memórias dinâmicas e, por isso, e também por causa da quantidade limitadíssima de armazenamento, eles só são usados em casos especiais.
Outras memórias estáticas além do latch:
Ficou claro que os pentes de memória espetados na sua placa-mãe são lentos? Existe um tempo mínimo para carregar e descarregar os pequenos capacitores contidos no interior dos circuitos integrados… Para melhorar a performance, usamos pequenas memórias RAM estáticas, no interior do processador, que chamamos de cache!
Este é o motivo pelo qual o cache L1 e L2 são relativamente pequenos (o cache L1 tem, hoje em dia, 32 KiB de tamanho para cada um de seus “galhos”: L1I e L1D, por exemplo)… Elas não podem ser grandes, porque seriam caras ($$) demais para que você pudesse ter um microcomputador em cima de uma mesa ou na palma da sua mão!
Outros flip-flops…
O mais importante aqui são os conceitos. Para os mais curiosos eu recomendaria a análise dos tipos de flip-flops pelo tipo RS, passando pelo D, pelo RST e indo parar no JK. Mas, essencialmente, tudo o que um desenvolvedor precisa saber é o funcionamento básico do tipo D e do modelo mestre-escravo.
No final dos anos 80 a IBM lançou o PS/2 (Professional System/2). Era “profissional”, ao invés de “Pessoal” (Personal Conputer) e possuia alguns recursos “avançados”, em relação ao PC. A arquitetura do barramento era a MicroChannel, bem mais versátil que o ISA (Industry Standard Architecture e o circuito de vídeo era melhor… Ao invés do CGA (Color Graphics Adapter) e EGA (Enhenced Graphics Adapter), a IBM estendeu a última e chamou de VGA (Video Graphics Array).
O padrão VGA persiste até hoje, ainda disponível nas placas de vídeo mais modernas. E não poderia ser diferente, já que todas as BIOS têm que ter um terreno comum para trabalhar.
É interessante ver que a maioria das pessoas lida com vídeo como se fosse algo mágico que só pode ser usado via rotinas da BIOS (aliás, a maioria dos dispositivos parecem funcionar por “mágica”). Aqui, quero estender um pouco o que já escrevi no meu antigo “Curso de Assembly da RBT” e explicar as entranhas da VGA.
Anatomia de um sinal de vídeo composto:
Para entender o que uma placa de vídeo faz é necessário entender como o sinal de vídeo é criado… Abaixo temos um exemplo de sinal de vídeo “composto” para uma única linha do padrão de teste mais famoso do mundo:
O padrão de teste gera uma onda característica.
O sinal é dito “composto” porque, num único sinal eletromagnético (transmitido por rádio) consegue-se montar uma imagem composta de quatro grandezas diferentes: Intensidade e as cores vermelha, verde e azul.
No exemplo do sinal, o pulso negativo, do lado esquerdo, é chamado de “pulso de sincronismo horizontal”. Este pulso faz com que o circuito de deflexão “puxe” o feixe de elétrons, do tubo de raios catódicos (CRT), para o início de uma linha, para a esquerda… Logo depois temos cerca de 9 ciclos de uma senoide de frequência de 4,43361875 MHz (PAL-M) ou 3.57954(54) MHz (NTSC) — o 54, entre parênteses é uma dizima periódica. Essa senoide é usada para sincronizar a fase dos circuitos de cor… Cores são calculadas como a diferença de modulação de fase da senóide de cada pixel em relação à fase deste sinal… Na figura acima, além das “cores” branca e preta, as demais são formadas pelo “nível de cinza” somado à senoide com fase específica para cada cor.
A cor branca é obtida quando o nível de sinal médio estiver em 100% e sem nenhuma portadora de cor. Se houver uma portadora de cor então o branco é somado a essa cor… O nível de preto é obtido um pouco acima do nível de referência zero. Isso porque zero é o nível do apagamento do feixe de elétrons, em preparação para um retraço. Embora o nível de apagamento seja um pouquinho mais negativo, para garantir que o feixe esteja realmente apagado!
Cada linha de um quadro segue esse padrão… Ao final de um quadro, acontecerá uma mudança no sinal de vídeo: Os pulsos de sincronismo horizontal ficarão mais frequentes (menos espaçados), depois maiores… Isso indica um sincronismo vertical, onde o feixe de elétrons é “levado” para o topo da tela novamente:
Sincronismo vertical entre quadros
No diagrama acima podemos ver que o tempo de uma única linha, entre os pulsos de sincronismo horizontal, é de cerca de 63,5 μs. O tempo desses pulsos diminui pela metade na preparação para sincronismo vertical (pulsos de equalização). Seque-se pulsos com a mesma frequência, mas duração maior, e mais pulsos de equalização… Estamos agora no topo da tela, de novo….
É importante notar que um sinal de vídeo não é feito apenas de pixels. Aliás, não existem pixels num sinal de vídeo… O feixe de elétrons vai varrendo a linha e sendo modulado para excitar mais ou menos um dos emissores de luz na grade perto do observador. Os “pixels” existem nesta grade…
Aliás, é comum encontrar a sigla PEL, ao invés de “pixel”, na literatura especializada… Usarei PEL, daqui por diante. Outro termo muito usado é “scanline” ou “linha de varredura”. Basta lembrar que o feixe “varre a linha”…
No sinal, acima, o intervalo para cada PEL não é visível, mas, considerando que o intervalo de uma linha (1H) tem 63,5 μs, o período de um único ponto é bem menor. De fato, no padrão VGA, a frequência de clock que domina a geração dos PELs é, no mínimo, de 25 MHz. Essa frequência é chamada de dot clock. Toda temporização tem, como base, essa frequência (existem frequência alternativas para resoluções maiores, como 28 MHz — a SuperVGA, com resoluções ainda maiores e frequências de varredura vertical grandes [frames por segundo] usa dot clocks ainda maiores). Veremos adiante como isso é usado na controladora CRTC.
Resolução gráfica
Existem dois fatores que determinam a resolução gráfica de um modo de vídeo no padrão VGA: A polaridade dos sinais de sincronismo e a quantidade máxima de caracteres (sim! caracteres!) numa scanline.
As maiores resoluções verticais são obtidas com a polaridade negativa do sincronismo vertical (350 ou 480 linhas). A polaridade positiva nos dá 400 linhas… A seleção das duas maiores possíveis resoluções verticais é obtida de acordo com a polaridade dos pulsos de sincronismo horizontais… Se os pulsos forem também negativos, temos 480 linhas, caso contrário, 350.
Até então, vimos apenas a resolução vertical — com um detalhe: ambos os sinais de sincronismo com os pulsos “positivos” são proibidos! — E esse tipo de seleção só funciona se o monitor CRT for multisync. É o que todo monitor CRT VGA é! Mas, e quanto à resolução horizontal?
Lembre-se que apenas os pulsos de sincronismo precisam ser… eh… como direi?… sincronizados! CRTs são dispositivos analógicos que, em teoria, podem suportar qualquer resolução gráfica possível, com a restrição feita apenas pela máscara dos elementos emissores de fótons (que tem gente que insiste em chamar de fósforo!). A resolução vertical é fixada pelos sentidos dos pulsos de sincronismo, já a resolução horizontal depende somente dos registradores de controle horizontal do CRTC (citado abaixo). Em teoria uma placa VGA poderia mostrar uns 2000 PELs na horizontal. Na prática, no máximo, chega a 720.
VGA é composta de 4 controladores:
A especificação original do padrão VGA (e do padrão XGA) da IBM pode ser obtido aqui. Além dos livros de Richard Ferraro e Michael Abrash, este é o material de referência primordial para o entendimento do funcionamento desse circuito gráfico.
Existem, pelo menos, 4 chips dedicados numa placa VGA: Um que controla o monitor de vídeo (CRTC), um que controla a ordem com que os dados chegam ou saem da placa (Sequencer), um que controla a geração de cores (Attribute Controller) e outro que faz a interface entre o computador e as entranhas da placa (Graphics Controller):
CRTC: Literalmente CRT Controller. O objetivo dessa controladora é a geração dos sinais de sincronismo, apagamento do canhão de elétrons e a temporização dos pulsos de retraços horizontal e vertical. Ele não lida com o sinal “visível” da imagem. Isso fica à cargo das outras controladoras;
Sequencer: O sequenciador é a controladora que decodifica endereços de memória vindas do barramento do sistema e também mantém os contadores internos que “sequenciam” o acesso à memória de vídeo, interna, para a geração da imagem — falarei da diferença dessas duas memórias mais adiante;
Attribute Controller: Esta a controladora que lida com cores. Ela é quem mantém a paleta de cores (dentre as 262144 cores possíveis para a VGA). Ela também decodifica atributos nos modos alfanuméricos;
Graphics Controller: Essa controladora faz a interface com o barramento do sistema e as outras controladoras. É através desta controladora que informamos se estamos lidando com o modo gráfico ou alfanumérico, por exemplo.
Cada uma dessas controladoras é programada através de um par de potas de I/O: Uma que indica um registrador e outra onde um dado pode ser lido ou escrito.A única controladora que foge um pouco a esse padrão é a Attribute Controller, onde a mesma porta é usada para informar um registrador e, logo em seguida, estará disponível para escrita. Há uma outra porta diferente para leitura.
Existe um quinto circuito, essencial, chamado RAM DAC. Já falei sobre os DACs aqui antes, mas esse é diferente… Ele não só converte o nível de tensão na saída de vídeo, mas as fases do sinal de crominância de cada PEL. Claro, que isso só é feito no caso de saídas em vídeo composto (aquelas saídas RCA, quando há). Os sinais de sincronismo e R,G e B são separados no conector VGA, o que torna tudo um pouco mais simples.
Registradores não associados à controladoras:
O padrão VGA oferece 4 registradores para controle e obtenção de status genérico. O registrador Miscelaneous Output ligado à porta 0x3CC (leitura) e 0x3C2 (escrita) controla o sinal dos pulsos de sincronismo, seleciona o dot clock, habilita a decodificação dos endereços do frame buffer e se estamos trabalhando no modo monocromático ou colorido. Este é o primeiro e principal registrador genérico da VGA.
É bom notar que a porta 0x3C2 pode ser lida, mas neste caso ela fornece o conteúdo do registrador Input Status 0. Cujo único bit significativo é o 7, que indica se a placa está efetuando um retraço vertical ou não. Esse bit é bem útil, porque é mais interessante atualizar o frame buffer durante um retraço vertical por dois motivos:
O circuito da placa de vídeo não vai colocar wait states no barramento para não competir com a tentativa de escrita do processador, durante um rertaço vertical;
O retraço vertical é a etapa de sincronismo mais longa do que os retraços horizontais!
Fazer isso evita o efeito de flickering…
Os outros registradores genéricos são reservados e não devem ser tocados (a não ser pela BIOS!).
CRTC e a temporização do sinal:
A controladora CRTC é a mais complicada das quatro e têm 25 registradores que precisam ser programados corretamente para a temporização certeira do sinal de vídeo. Estranhamente, não é apenas o sinal de vídeo que deve ser corretamente temporizado, mas também os intervalos usados para a geração de um “cursor”… O diagrama abaixo mostra um resumo do modelo usado pela controladora em relação aos sinais de temporização:
Temporização VGA
Todos dos ajustes horizontais são medidos em termos de caracteres, não em PELs. Em certos modos de vídeo um caracter é definido como tendo 8 PELs na horizontal, em outros, 9. Suspeito que a escolha por medir “por caracter” tenha sido feita dessa maneira para evitar o uso de muitos bits em cada um dos registradores. Repare, por exemplo, que o registrador Horizontal Total contém a quantidade de caracteres na linha, incluindo o tempo do retraço horizontal menos 5.
Os ajustes verticais são mais simples. São medidos em scanlines (ou, simplesmente, linhas). Em teoria, poderíamos ter resoluções de até 1024 linhas numa VGA já que esse registrador tem 10 bits de tamanho. Com tantos bits, não é possível usar um registrador só para conter o valor… É o caso, por exemplo, do registrador Vertical Total, que possui 8 bits, mas os dois bits superiores estão no registrador Overflow.
Do ponto de vista de um monitor de vídeo, o CRTC é a controladora mais crítica… Alguns velhos monitores CRT sobreaquecem se as frequências horizontal e vertical excederem certos valores e já vi casos de monitores pegando fogo, literalmente… Algumas placas de vídeo antigas também sofriam desse mal: Algum chip sobreaquecia e “puf”… Felizmente isso não acontece mais…
Sequencer:
O sequenciador controla a sequência de eventos (óbvio!), mantendo, inclusive, contagens para geração de caracteres e para divisão do dot clock (no caso de resoluções menores). Ele têm apenas 5 registradores.
O primeiro deles é importante quando estamos programando um novo modo de vídeo. Trata-se do registrador de reset do Sequencer. É importante que façamos um reset síncrono, o que zerará os contadores do sequenciador e o colocará num estado de “parado”.
Outro registrador do sequenciador importante é o Clocking Mode, que altera a semântica do dot clock. O bit 0, por exemplo, diz se estamos usando caracteres de 8 ou 9 pontos na horizontal (o que afeta os ajustes no CRTC).
Aqui também habilitamos ou não os “planos” da memória de vídeo usadas no novo modo de vídeo. Alguns modos usam um conjunto limitado de “planos”, outros usam todos eles… Como saber quais mapas devem ser usados? Existe outro registrador do sequenciador para isso: O Memory Mode…
Depois que as outras controladoras forem programadas podemos zerar o bit de reset e o sequenciador recomeçará a seguir o seu curso.
Attributes Controller:
A maioria dos registradores da controladora de atributos lida com cores. Os 16 primeiros registradores são índices para o mapa de cores das 16 cores iniciais (a maioria dos modos coloridos de vídeo da VGA são de 16 cores). Os demais lidam com a geração de cores… são apenas 5 registradores.
Graphics Controller:
O ajuste do modo de vídeo e a manipulação da memória do frame buffer versus memória de vídeo são feitas aqui. Temos apenas 9 registradores. Aqui podemos, além de outras coisas, selecionar quais “planos” serão alterados ou lidos, selecionar quais bits dos bytes desses planos serão alterados ou lidos, etc… Quando você pensa em lidar com a memória de vídeo (seja o frame buffer, seja a memória interna, pensa nessa controladora!).
O que são o Frame Buffer e memória de vídeo
Se você já mexeu com a “memória de vídeo”, gosta de pensar nela, em modo real, como localizada no endereço lógico 0xA000:0x0000 (no modo 320x200x256) ou 0xB800:0x0000 (no modo texto, colorido, de 80×25). No entanto, essa não é a memória de vídeo. Isso é o frame buffer.
A memória de vídeo encontra-se dentro da placa de vídeo e é acessada através do frame buffer. O padrão VGA possui 4 blocos de 64 KiB chamados “planos”, numerados de 0 a 3. No caso do modo de vídeo, texto, 80×25, três planos estão habilitados: O plano 0 contém os caracteres a serem desenhados na tela, o plano 1, os atributos de cada um desses caracteres e o plano 2 contém os bitmaps das fontes usadas no desenho. Todos os planos começam no endereço zero e, assim, nos planos 0 e 1, o endereço zero contém, respectivamente, o caracter no canto superior direito e seu atributo.
No frame buffer, acessível pelo processador, os planos 0 e 1 são mapeados de forma intercalada (num modo conhecido como Odd/Even ou, Par/Ímpar). Onde os endereços pares são mapeados para o plano 0 e os ímpares para o plano 1… No modo 80×25, o plano 2 não é acessível pelo frame buffer diretamente. Ele é preenchido pela BIOS antes do ajuste do modo para que o circuito da placa saiba como desenhar os caracteres.
Nos atributos de um caracter, o bit 3 é, normalmente, usado como “intensidade” da cor de frente, mas o controlador de atributos pode ser reprogramado para interpretá-lo como “mapa do bitmap da fonte”, do plano 2 (neste artigo mostro como obter o bitmap usado pela BIOS). Isso permite que, em modo texto, possamos embelezar um bocado nossas aplicações, como é o que acontece com o Norton Utilities 6, para MS-DOS:
Norton Utilities Control Center
Acredite, a tela acima está totalmente em modo texto! O que o utilitário fez foi criar alguns caracteres especiais no segundo bitmap disponível para o padrão VGA para “fazer de conta” que encontra-se num modo gráfico. Embora o modo texto seja evidente, o efeito final (com o botão de menu de janela e as bordas branquinhas) fica bem interessante.
Em outros modos, o mapeamento dos planos de vídeo em relação ao frame buffer é mais complicado. Num modo 640×480 de 16 cores, os 4 planos são mapeados para o frame buffer, um por vez. Cada byte do frame buffer é mapeado diretamente para 8 PELs, um bit por vez. Se cada plano possui um bit de um pixel, então cada bit de cada plano forma um PEL. Num único PEL o bit 0 estará no plano 0, o bit 1, no plano 1 e assim por diante.
Esse esquema planar permite que um modo de 640×480 com 16 cores, que ocuparia 150 KiB ( PELs). Agora ocupa 38400 bytes por plano (). Como o frame buffer é limitado a 128 KiB (de 0xA0000 até 0xBFFFF), esse esquema funciona muito bem, mesmo que seja complicado.
SuperVGAs
O “Super” de SuperVGAs tem a ver com a resolução máxima suportada pela placa de vídeo, bem como a quantidade máxima de cores dessas grandes resoluções. O padrão é derivado do XGA, da IBM, mas foi proposto pela VESA (Video Electronics Standard Association)… A VESA surgiu em 1988 por iniciativa da empresa japonesa NEC (Nippon Electric Company) que propôs a associação justamente para a criação do substituto para o padrão VGA.
Em 1991 surge a SuperVGA. Infelizmente, já que mais de 200 empresas participaram do grupo, hoje temos uma miríade de implementações que torna impossível chamar SuperVGA de “padrão”…
Em essência, o que o SuperVGA faz é estender alguns registradores dos controladores da VGA (para suportar mais cores e mais resolução gráfica) e implementar um esquema de “janelas” no uso do frame buffer para acesso à memória de vídeo. Por que? Ora, uma resolução gráfica de 800×600 com 65536 cores exige 2 bytes por cor e, portanto, o total de memória necessária para armazenar isso tudo é de quase 1 MiB! Lembre-se que o nosso frame buffer tem, no máximo, 128 KiB… Assim, a SuperVGA quebra a tela em janelas ou “faixas”. No caso dessa resolução (800×600 com 64 Kcores), é provável que a tela seja dividida em 15 faixas de 40 linhas… Assim, se cada linha tem 1600 bytes de tamanho (), então 40 linhas ocuparão, aproximadamente, 64 KiB que, além de caber totalmente dentro da faixa do limite de 128 KiB imposta pelo frame buffer, permite até o uso de duas “páginas”!
Sempre que tivermos que desenhar um pixel dentro de uma faixa, pedimos a placa para trocar o mapeamento da “janela” no frame buffer e lidamos com a nova faixa. Dá um baixa trabalho, mas com o surgimento dos PCs de arquitetura de 32 bits (386) e com mais memória RAM, o padrão VESA evoluiu e permitiu a alocação de frame buffers fora da região do padrão VGA. A especificação da arquietura AGP (Advanced Graphics Port), por exemplo, sugere uma “abertura” de 1 MiB acima do limite de 15 MiB de RAM, didicada ao linear frame buffer. No exemplo acima, 800×600 com 64 Kcores,
Aceleradores 2D
A IBM, é claro, retrucou… Surge o acelerador gráfico 8514/A (datasheet aqui — mas, não se anime, ele é obsoleto!). Além de suportar o “padrão” SuperVGA ele oferece recursos de cópia de blocos diretamente da memória de vídeo (note bem, não do frame buffer!), chamado de bit block tranfer (BitBlt — se você já viu a GDI do Windows, já deve ter se perguntado muito o que essa “palavra” esquisita significa, huh?), a capacidade de preencher áreas por hardware e a de desenhar linhas do mesmo modo…BitBlt oferece o recurso primitivo de texture mapping, mas apenas de blocos retangulares alinhados com os eixos. Ao invés de “texturas” eles recebem o nome de sprites.
A partir dai, já que a padronização “virou bagunça”, começaram a surgir um monte de aceleradoras… Algumas empresas já existiam como a ATI, mas apareceram muitas outras: ALi, Trident, Matrox, Cirrus Logic, Chips & Tech, S3, SiS, Tseng etc etc…Cada uma com suas aceleradoras próprias e conjuntos de registradores diferentes.
O único material que encontrei sobre os diversos registradores de fabricantes diferentes está contido numa série de documentos texto, antigos, de 1995 (baixe-os aqui se estiver curioso).
GPUs
Claro que, hoje, a tendência é a substituição de todo o recurso gráfico compatível com a VGA pelas GPUs… Especialmente porque todos os recurso de aceleração 2D podem ser substituídos por shaders, se necessário. Ainda, texture mapping é real aqui, usar sprites é um caso especial. E, por fim, as GPUs modernas têm centenas (senão milhares) de “núcleos” de execução individuais…
Mas, é claro, são complicadas pra caramba de usar se você é um desenvolvedor de sistemas operacionais. Os fabricantes não costumam divulgar informações detalhadas (se é que divulgam alguma!) com explicações coerentes sobre os registradores e seus usos. Pelo menos a nVidia não o faz (e ganhou um merecido “fuck you!” de Linus Torvalds por isso!), mas a AMD (atual dona da ATI) e Intel divulgam, mesmo que pareça material para magia negra!
E ainda tem o problema que são daughter boards, ou seja, placas que são espetadas na placa mãe… Ou seja, a BIOS não tem como prever o que elas têm, por dentro. Enquanto isso, o padrão VGA estará conosco por muito tempo ainda…
O que eu espero que você entenda deste texto
Ora… claramente eu só fiz um overview sobre o funcionamento de uma placa de vídeo VGA e falei menos ainda sobre as SuperVGAs. O importante é que você saiba que nenhum recurso dessas placas existe à toa.
Alguns destaques para o começo de suas pesquisas já foram dados:
Em linhas gerais, a função de cada controladora;
Como a CRTC tem que ser manipulada;
Detalhes mínimos sobre o Sequencer;
O restante é mais simples (baixe a documentação e estude)…
Ahhhh… sim… um detalhe: É importante que, ao lidar com a placa VGA diretamente, as interrupções estejam desabilitadas!
Citei apenas duas tecnologias aqui porque são as mais usadas: TTL e CMOS. No entanto, é claro que existem outras, mais antigas, fora de uso, e algumas mais recentes e ainda pouco usadas.
Tecnolgias velhas e obsoletas
Antes dos TTLs existiam, por exemplo, as RTLs (Resistor-Transistor Logic) e DTLs (Diode-Transistor Logic). A primeira é bem simples de explicar e está presente em amplificadores simples, como mostrada ao lado… É óbvio que o transístor T1 conduzirá apenas se a entrada A estiver ligada a VCC e, neste caso, entrará em saturação, reduzindo a resistência coletor-emissor a praticamente zero, colocando a saída Q em zero… Caso contrário, se A for ligado a GND, a saída será colocada em nível alto através do resistor R2.
O nome RTL também é óbvio: A entrada A está conectada a um resistor e a saída Q a um transístor.
A outra tecnologia obsoleta, DTL usa diodos como entrada. Se IN for GND a tensão não chegará a 0,6 V e o transístor não conduz, colocando nível alto na saída. Se IN for ligada em +5 V então o diodo de entrada não está polarizado e em corte, daí a junção base-emissor do transístor estará diretamente polaraizada, colocando zero na saída…
Simples, huh? Qual é o problema dessas configurações?
No caso do RTL o que temos é um amplificador inversor simples… A saída será diretamente proporcional à tensão da entrada e, por isso, não se pode garantir os “níveis” binários. E, no caso do DTL, não há “separação” eficiente dos níveis. Se a entrada estiver em +4,4 V, o diodo de entrada conduzirá. Apenas valores maiores que esse são interpretados como “alto”… Ou seja 88% de toda a faixa é interpretada como “baixo” e apenas 22% como “alto”.
Tecnologias novas e ainda não totalmente em uso
Além das TTL e CMOS temos coisas como BiCMOS que mistura MOSFETs com BJTs… Os BJTs têm a vantagem de serem mais rápidos que os MOSFETs, desde que ambos tenham características físicas similares. Assim, alguns CIs e microprocessadores (os atuais processadores da família Intel usam BiCMOS!) fazem essa mistura.
BiCMOS é muito complicado de explicar aqui e eu não vou nem tentar… Fique ciente que existem técnicas mais recentes que TTL e CMOS, mas todas elas são bastante similares a essas duas.
E, é claro, existem pesquisas sendo feitas com transístores quânticos. Coisa que não faço a menor ideia de como funcionam a não ser por um conceito geral sobre quantum entanglement… Conceitualmente, a ideia é usar a menor quantidade possível de matéria (umas poucas moléculas) para obter o mesmo efeito do transístor (amplificação). E a lógica booleana de 1’s e 0’s vai pro beleléu com isso…
Você já deve ter ouvido falar das válvulas, certo? Mas, assim como eu, provavelmente nunca trabalhou com uma… Como elas surgiram e como funcionam?
No final do século XIX, em 1875, Alexander Graham Bell e dois empresários, criaram a empresa de telefonia American Telephone & Telegraph Company, conhecida por sua sigla, AT&T. A empresa explora (até hoje) a invenção de seu proprietário e, como se podia esperar, ganhou muito dinheiro… A gigante das telecomunicações americana começou logo a sofrer com a perda da patente do seu produto (o telefone)… Explico: Patentes têm tempo de vida limitado, especialmente se o assunto é de interesse público. Depois de alguns anos a patente torna-se de “domínio público”, podendo ser explorada por qualquer um…
No início do século XX a AT&T viu-se perdendo clientes porque diversas pequenas empresas estavam criando suas próprias “redes” de pequeno alcance com custos mais baratos. A solução? Ela precisava oferecer serviços de telefonia (voz) para longas distâncias… Isso era um grande problema, na época, já que amplificadores simplesmente não existiam. O sinal elétrico sofre perdas e chega, do outro lado dos fios, baixinho… É preciso amplificá-lo e retransmití-0, digamos, a cada quilometro de distância da fonte.
A primeira válvula e seu símbolo
Embora em 1904 já existissem diodos explorando o que os físicos da época chamavam de termiônica (é uma espécie de “eletrônica” via efeitos térmicos), em 1906 um físico contratado pela AT&T para resolver o problema da amplificação descobriu que poderia inserir uma “placa” entre o filamento (fonte de elétrons) e o anodo (receptor do fluxo de elétrons) e controlar esse fluxo. A placa, ou grade, funciona como se fosse uma porta: Quanto mais “aberta”, mais elétrons passam. O nome dado a tal dispositivo foi “triodo”. Surge o primeiro amplificador.
Com o triodo pode-se controlar o fluxo de elétrons, entre o anodo e o catodo, fornecido pelo filamento, através do “gate”… A tensão entre o “gate” e o catodo é pequena, para uma modulação suficiente do fluxo entre A e K. E, voilà! Agora era possível amplificar e retransmitir sinais em grandes distâncias… A primeira linha telefônica de longa distância (da costa leste à costa oeste dos EUA) foi criada. Logo seguiu toda a infraestrutura para abraçar todo o país.
Claro que existe um problema extra: Com a termiônica existe a tendências das coisas “queimarem”! Válvulas tinham vida curta. Paravam de funcionar com facilidade. Era necessário descobrir uma maneira mais duradoura. E, até meados do século XX, uma outra disciplina estava em estudo para substituir a terminônica: Ao invés de lidar com efeitos térmicos, por que não lidar com efeitos quânticos? A mecânica quântica estava começando a fazer algum sucesso no início do século XX, mas ninguém a entendia direito… O único efeito prático, em termos de “eletrônica”, era o do diodo… Mas, tinha que ter um jeito de criar uma válvula “eletrônica”… Tinha que ter…
Pouco antes da 2ª guerra mundial a AT&T financiou um grande “laboratório” de pesquisas: Bell Labs. Obviamente, um dos interesses era descobrir um bom substituto para a válvula. Trabalho que ficou a cargo de um físico teórico chamado William Schokley. Embora brilhante, o sujeito era ruim com experimentos e não tinha lá muita experiência com “eletrônica”. Dois outros físicos juntaram-se à equipe: Um físico experimental e outro, teórico, especializado no comportamento de elétrons em sólidos. Levou uns bons anos para descobrirem o transístor… E aqui a história do FET começa.
O transístor de efeito de campo foi um fracasso!
Elementos semi-condutores têm algumas características interessantes, se comparados com metais… Eles não conduzem tão bem (mas, não são isolantes) e, quando submetidos a aumento de temperatura, ao invés de oferecerem mais resistência elétrica, oferecem menos. Quanto mais quentes, mais conduzem…
Não é o ocorre num fio de cobre, por exemplo… Esse fato, em si, tem consequências interessantes para o desenvolvimento da eletrônica… Nas válvulas um filamento tem que ser aquecido através da aplicação de uma corrente elétrica. Quanto mais quente, mais corrente precisa. Daí, válvulas consomem muita energia somente para manter a fonte de elétrons “a pleno vapor”. Não é o que parece acontecer com os semicondutores como Germânio e Silício… Eles conduzem melhor quentes! Isso significa que não é preciso aquecer um semicondutor para obter o mesmo efeito do triodo…
Isso já era sabido nos anos 40, pelo menos hipoteticamente… Schokley teve uma ideia: E se eu “puxasse” as cargas livres de um elemento semicondutor para a superfície? Isso formaria um “canal” onde os elétrons poderiam fluir mais facilmente! Esse negócio de “puxar” as cargas livres pode ser conseguida por um efeito capacitivo: Coloca-se uma placa metálica sobre uma barrinha de Germânio ou Silício, sem que elas se toquem, e carrega-se positivamente a placa. No cristal semicondutor as cargas negativas livres deverão se aproximar da superfície formando um canal, fazendo a configuração eletrônica do cristal deixar de ser caótica e tornar-se ordenada, facilitando o fluxo de corrente elétrica…
Foi uma excelente ideia! Pena que não funcionou.
É claro que, praticamente toda a nova eletrônica de hoje em dia é baseada precisamente neste princípio. Descobrimos o que Schokley fez de errado em seu experimento. Mas, na época, o “efeito de campo” foi abandonado e o que se seguiu deu origem ao transístor de junção…
O transístor de efeito de campo (FET):
A ideia de Schokley é o que chamamos, hoje, de MOSFET. Eis como funciona:
Como o MOSFET funciona.
Queremos controlar a corrente circulando entre os terminais Source e Drain. O terminal Gate é ligado a uma placa metálica, separada do cristal P por uma camada isolante de óxido de silício (SiO2), formando um pequeno capacitor. Ao ser carregado positivamente, forma-se uma canal de cargas negativas no cristal P perto do gate. Cria-se um “campo” eletrostático que é como se transformássemos esse pedaço do cristal P em cristão N, fechando o circuito entre os dois cristais N.
O experimento de Schokley falhou por diversos motivos. Dentre eles, a pureza dos cristais e o desconhecimento da barreira de potencial das junções…
O diagrama acima é apenas um exemplo. O capacitor formado pelo substrato P e o gate é feito de outra forma. Existe um quarto terminal, o Bulk ou Body. Abaixo temos o símbolo de um MOSFET de canal N, à esquerda, e o diagrama esquemático de sua configuração:
Os MOSFETS de canal P têm, na simbologia, a setinha no sentido contrário.
A vantagem do MOSFET sobre o BJT
Ambos MOSFET e BJT sofrem com algum efeito capacitivo… Uma junção é obtida por uma reação química, introduzindo impurezas no cristal, aumentando a quantidade de “cargas livres”, sejam “lacunas” ou cargas negativas… Há uma divisão de materiais e é como se existisse uma pequena região isolada entre os cristais. É claro que esse isolamento é tão pequeno que o efeito capacitivo é insignificante, mas ele existe… Os MOSFET também o têm porque causa das duas junções entre o substrato e os cristais ligados à fonte e dreno…
A vantagem real do MOSFET é que no capacitor existente entre o Gate e o Body só haverá fluxo de cargas (corrente elétrica) no momento de sua carga ou descarga. Uma vez que a carga é estabelecida, não há consumo de energia! Ou, pelo menos, é bem próxima de zero. Isso difere um bocado dos BJT, onde a polarização direta base-emissor é essencial para o efeito de amplificação.
Outro detalhe é que, em teoria, podemos fazer o espaço entre os cristais ligados à fonte e ao dreno tão próximo quanto possível. O transístor pode ser miniaturizado em escalas moleculares! Isso não é possível com o BJT, onde o tamanho do cristal da base, em relação aos outros dois, é importante.
De fato, se você der uma olhada nas especificações de microprocessadores modernos, verá algo como “usando tecnologia de 32 nm”. O limite prático para o distanciamento dos cristais parece girar em torno dos 25 nm, em microprocessadores mais recentes. Para conseguir isso, tensões e correntes cada vez menores são usadas nas especificações dos circuitos…
Alguns amigos expressaram suas preferências por um outro tipo de transístor. o FET (Field Effect Transistor, ou “Transístor de Efeuti de Campo”), mais especificamente o MOSFET (Metal Oxid Semiconductor FET). Eu e toda a indústria de microinformática compartilhamos dessa preferência… E falarei sobre esse tipo de transístor no próximo artigo. Antes, é conveniente entendermos o funcionamento do tipo de circuito lógico mais difundido na história da eletrônica digital: O TTL.
TTL é a sigla de Transistor-Transistor Logic. Significa que, no circuito integrado, o componente de entrada é um transístor e o de saída também é. Esse tipo de circuito ainda é usado, especialmente com circuitos que contenham microcontroladores que trabalham em “baixa” frequência de clock (alguns MHz!)…Embora não sejam o crème de la crème da tecnologia digital, eles são de fabricação bem mais barata do que as tecnologias mais recentes. E são eficientes.
Portas lógicas são uma abstração conveniente:
Para o não iniciado, circuitos lógicos são compostos de portas lógicas e alguns blocos mágicos que operam de acordo com algum algoritmo arcano. No entanto, esses circuitos lógicos são feitos de circuitos discretos mais elementares: Transístores, diodos, resistores e capacitores… É importante conhecê-los para entender seus limites, características e usos. Por exemplo, a saída de uma porta lógica TTL padrão pode fornecer (ou consumir) correntes máximas de 16 mA (para saída em nível baixo) e 400 μA (para saída em nível alto). Se seu circuito tentar “drenar” correntes maiores que essas o circuito integrado vai ser danificado. A mesma coisa se aplica à entrada. Correntes maiores que 1,6 mA (para nível alto) e 40 μA (para nível baixo), na entrada, faz com que o chip faça “puff” e saia uma fumacinha fedorenta…
O circuito simplificado de uma porta inversora:
O circuito abaixo é o equivalente usado na família TTL. Mais especificamente o 7404. Retirei algumas coisas, como o diodo de proteção da entrada, para simplificar a análise. Estou também usando o circuito TTL típico e menos especializado… Alguns membros da família TTL são mais complexos porque superam os limites de velocidade e consumo de corrente usando coisas como diodos e transístores Schottky, por exemplo. Esses outros circuitos podem ser encontrados em datasheets e são bem mais chatos de entender…
Porta lógica inversora TTL padrão
Para analisar o circuito acima vamos aplicar as tensões VCC e GND na entrada A e ver o que acontece na saída Y… Nos TTL padrão a tensão de alimentação VCC é de +5 V.
De acordo com o que sabemos sobre portas inversoras, se aplicarmos VCC na entrada A, a saída Y deverá ir para nível baixo (GND) e, se colocarmos GND em A, Y deverá estar em nível alto (VCC). Para continuarmos a análise adotarei 4 pontos de teste de tensão nomeados de V1 até V4, conforme indicados abaixo:
Analisando o circuito lógico:
Já sabemos que um BJT só conduz se a tensão . Qualquer valor menor que esse e ele estará em corte. No circuito acima, a configuração estranha do transístor Q1 indica que ele é usado apenas como dois diodos em oposição.
É evidente que se A for VCC, então o diodo entre base e emissor de Q1 estará em corte. Isso significa que o transístor Q2 estará polarizado corretamente e conduzindo, já que teremos três diodos diretamente polarizados e em série (o diodo base-coletor de Q1, o diodo base-emissor de Q2 e o diodo base-emissor de Q4). Quanto ao em Q4, é bom notar que o resistor R4 está em paralelo ao diodo da junção BE do transístor. Será a corrente de Q2 que fará com que V4 seja aproximadamente 0,6 V, mas a tensão é mantida nesse valor graças ao diodo em Q4.
Assim, Q4 poderá estar conduzindo (depende da carga em Y). Mas, e quanto a Q3?
Note que, se Q2 está em saturação, a tensão V3 é aproximadamente igual a tensão V4. Mas, mesmo que a saída Y esteja ligada diretamente a GND, a tensão necessária, em V3, para que Q3 conduza é de cerca de, pelo menos, 1,2 V (a tensão de Q3 mais a tenão de barreira do diodo na saída). Mas, só temos, aproximadamente, 0,6 V em V3, ou seja, Q3 estará com certeza, em corte.
O circuito, simplificado, para quando A estiver conectado em VCC é o mostrado à esquerda, na figura abaixo, onde o diodo é a junção BC de Q1:
Agora, se colocarmos A ligado à GND o diodo base-emissor de Q1 estará diretamente polarizado e conduzindo. Isso coloca a tensão V1 em 0,6 V. Dessa forma, o diodo base-coletor de Q1 não poderá conduzir por causa daqueles 3 diodos em série que citei antes. Teríamos que ter, no mínimo 1,8 V em V1 para o diodo base-coletor de Q1 conduzisse… Assim, Q2 e Q4 estarão em corte. O que faz com que Q3 esteja diretamente polarizado (se tivermos carga), colocando nível alto na saída! Isso é mostrado no circuito simplificado do lado direito, na figura acima. O diodo ligado a R1 é a junção EB de Q1.
Nesse cenário podemos inferir que a tensão de entrada mínima para que uma porta lógica TTL encare o sinal como “nível alto” é de 1.2 V (as tesnões de Q2 e Q4, ou seja, a tensão mínima necessária em V2). Infelizmente a coisa não é bem assim…
Faixas assimétricas:
Porque os circuitos integrados TTL usam BJTs que podem trabalhar na região ativa (fora das regiões de corte e saturação), as faixas de valores de tensão de entrada e saída, interpretadas como nível alto e baixo são diferentes e assimétricas. Eis as faixas, em escala, para o padrão TTL:
Na entrada, de GND até 0.8 V temos a garantia de que o “nível” de entrada é “0” (baixo). Qualquer coisa acima disso, até o limiar que chamei de ponto “indefinido” tem probabilidade menor de ser interpretado como “0”. A mesma coisa é válida para nível alto: De +2 V até +5 V (a tensão nominal de circuitos TTL) e teremos entrada em nível alto.
Note que a saída possui faixas diferentes das da entrada.
Essas “garantias” têm a ver com os dois transístores, Q3 e Q4, na saída. Esses níveis de tensão na entrada são garantias de que apenas um dos dois transístores de saída estejam conduzindo. Com valores de entrada mais “incertos”, ambos podem estar conduzindo com “resistências diferentes”, onde um terá mais influência do que outro.
Outro detalhe é que as tensões de saída dependem da carga conectada à saída Y. Note que, no caso do nível alto de saída, existe um resistor R3 que causará queda de potencial de acordo com a corrente sendo drenada da fonte de alimentação. Há outra queda de potencial no diodo, em série com o emissor de Q3. Portanto, nível alto, na saída, jamais poderá alcançar o patamar de 5 V, quando há carga.
No caso da saída em nível baixo, o transístor Q4 dita, junto com a carga, a tensão de saída… Como ele, geralmente, estará saturado, essa tensão costuma ser bem próxima de zero.
A assimetria das faixas dos níveis lógicos e das entradas e saída dos TTL é esquisita à primeira vista, mas é útil: Se tivermos nível baixo na saída de uma porta lógica, teremos, pelo menos, 0.4 V. As perdas em fios, ou trilhas numa placa de circuito impresso, diminuirão a tensão, que continuará sendo zero… Mas, mesmo que por um efeito de indução alguma tensão seja adicionada, na entrada de outra porta lógica pode chegar até o dobro dessa tensão máxima (de saída) que continuará sendo interpretado como nível baixo! O mesmo acontece com o nível alto… Se perdermos 0.4 V na saída (cujo mínimo de saída, garantido, é 2.4 V), a entrada de outra porta, ainda assim, encarará 2 V como nível alto, garantidamente.
A desvantagem da tecnologia TTL:
A grande desvantagem dos TTL não é o tamanho do circuito (os cristais dos coletores costumam ser maiores que os dos emissores e, ambos, bem maiores do que os da base). Sobre isso falarei mais quando mostrar a tecnologia CMOS… Nem mesmo a velocidade é um problema. O que não agrada aos projetistas é a dissipação de calor!
Como TTL usa BJTs, que precisam estar polarizados, todo o circuito consome corrente mesmo se nenhum trabalho útil for feito (mesmo se a entrada A e a saída Y estiverem “em aberto”!). Ou seja, energia é gasta somente com a polarização, por assim dizer… Quando falamos de algumas poucas portas lógicas, isso não tem lá grande influência, mas num microprocessador, com “trocentos zilhões” de transístores, a capacidade de fritar bacon em cima do circuito integrado não é uma feature muito desejada.
Para mitigar problemas de temperatura, velocidade e outros, a família TTL não é monolítica. Ela é dividida em “séries”. Os circuitos integrados tem numeração iniciada com 74, seguido de algumas letras (se houverem) e outro número que corresponde ao circuito lógico implementado… Por exemplo, o 7404 é um “CI” que contém 6 portas inversoras, cujo circuito mostrei lá em cima… Mas, existe também o 74S04, 74LS04, 74HC04, 74ALS04 e um monte de outros… Cada um desses é um pouquinho diferente (mais rápidos, ou que consomem menos, ou compatíveis com CMOS, etc)… Existem séries que trabalham com VCC de +5 V, outras com +3,3 V e ainda outras com +1,8 V. E por ai vai…
Se você está curioso, disponibilizarei, mais tarde, Databooks antigos que contém uma lista com diversos modelos de “CIs” (Circuitos Integrados) TTL. Mas, prepare-se! A lista é enorme!
A família 54
Falei que os CIs da família 74 são TTLs… Mas as da família 54 também são! Qual é a diferença? A família 54 é mais “parrudinha”. Ela existe para aplicações militares… Normalmente os CIs da família 74 possuem invólucro plástico ou de alguma resina especial. Os da família 54 geralmente têm invólucro cerâmico. Eles aguentam temperaturas mais altas. Suspeito, ainda, que a família 74 use prata ou alguma liga mais baratinha para a ligação dos terminais externos com o die do CI, enquanto a família 54, provavelmente, usa ouro ou algum outro metal de alta condutividade e alto ponto de fusão…
Você já ouviu muito isso, não? “O processador têm trocentos zilhões de transístores!”, mas, o que diabos é um transístor?
O termo refere-se a uma analogia com os velhos potenciômetros (resistores variáveis). Ele significa, em inglês, “Transfer Resistor” ou, em tradução livre, “transferência de resistência”. Ao invés de variar a resistência entre dois terminais de maneira mecânica, girando ou deslizando um knob, um transístor usa um sinal elétrico.
Da mesma forma que um diodo, um transístor bipolar de junção tem cristais P e N, mas ao invés de apenas dois, tem três e em oposição (veja a figura abaixo)… Isso nos dá duas configurações possíveis: PNP ou NPN. Como temos três cristais e três terminais, teremos dois “polos”: Num transístor NPN (que é o que mostrarei aqui), temos uma polarização entre os cristais PN (de NPN) e outra entre os cristais NP (de NPN). O adjetivo “de junção” também já foi explicado quando falei dos diodos.
Eis o símbolo de um BJT (Bipolar Juntion Transistor) e um diagrama equivalente, em termos do arranjo dos cristais:
Símbolo e disposição simplificada
Os terminais B, C e E são chamados de Base, Coletor e Emissor, respectivamente. Esses nomes foram baseados na configuração das antigas válvulas onde um filamento era a fonte de elétrons livres (esquenta-se um filamento e forma-se uma “nuvem” de elétrons — percebida pela luminosidade). Esses elétrons livres são “coletados” por uma grade intermediária e “emitidos”, ou acelerados, para uma placa metálica… Embora não estejamos falando de válvulas, o princípio é semelhante: O diodo PN entre base e emissor serve para “arrastar” as cargas livres no cristal N do coletor em direção ao emissor.
Repare, no diagrama acima, no tamanho relativo dos cristais. O cristal P, na base, é mais fino que os outros dois e há um motivo para isso… Para explicar é necessário o uso de um circuito de polarização típico para um transístor NPN:
Polarização típica de um BJT NPN
O “diodo” entre B e E está diretamente polarizado e o diodo entre C e B tem que estar reversamente polarizado…Isso é fácil de observar se substituirmos o transístor acima por dois diodos:
Polarização dos diodos
Se a tensão da fonte de sinal (do lado esquerdo) tiver tensão suficiente, atingirá o ponto de condução deste diodo, fazendo com que as lacunas do cristal P e as cargas negativas livres do cristal N do emissor fiquem “alinhadas” (ao invés de aleatoriamente espalhadas) ou “juntinhas”. Já que o cristal da base é fininho, fica fácil uma carga negativa, na corrente real, pular do cristal N do emissor para o cristal N do coletor, passando pelo cristal P.
Se o diodo entre B e E não estiver conduzindo, ou seja, se , então as lacunas no cristal P não estarão alinhadas (ou “juntinhas”) e as cargas do cristal N no emissor estarão caoticamente espalhadas, impossibilitando a circulação de corrente entre o coletor e o emissor.
Com isso temos que a tensão controla a corrente de base que, por sua vez, controla a corrente de coletor . Pode-se inferir que o que estamos controlando, na realidade, é a resistência, imposta pelos cristais em oposição, entre o coletor e o emissor! Daí o nome do componente eletrônico.
De fato, a curva característica de , em função de , é a mesma de um diodo comum, mas a curva característica de versus , em função de , é mais complicada:
Curva característica de versus
Esta é a curva característica de um transístor NPN modelo BC548… O que essa curva demonstra é que é, nas condições certas, diretamente proporcional à corrente . Ou seja, dado uma escala , temos:
As curvas mostram outras coisas interessantes: Se, digamos, , não importa qual seja a tensão , a corrente será aproximadamente zero. Ou seja, resistência entre coletor e emissor tende a infinito. Neste caso é dito que o transístor está em corte. No outro caso, se , então a corrente tende a aumentar rapidamente, ou seja, a resistência é muito pequena. Neste caso é dito que o transístor está numa situação de saturação.
Transístores bipolares como chaves:
Em circuitos digitais é comum que transístores sejam usados, basicamente, nas condições de corte e saturação. É como se ele fosse uma chave. Se temos um circuito aberto entre o coletor e o emissor. Mas, se , a corrente será suficiente para colocar o transístor em saturação, reduzindo a resistência elétrica entre coletor e emissor bem próxima a zero, fechando o circuito. Note que se então será, necessariamente, zero…
Uma das tarefas do desenvolvedor de OSs é interpretar e implementar especificações relativas ao hardware como: Controladoras de teclado, disco, USB, Vídeo, memória, timers etc. Sem o conhecimento mínimo sobre eletrônica isso torna-se uma tarefa muito penosa. Nessa série de artigos eu pretendo oferecer noções fundamentais sobre eletrônica “analógica” e “digital” que podem te ajudar a entender melhor como o hardware de seu computador funciona.
Estou assumindo que o leitor tenha conhecimentos sobre eletricidade: O que é tensão, corrente, resistência elétrica. O que são e como funciona associações de resistores. O que é e como funciona um capacitor e um indutor… Tudo isso é assumido como conhecido. O ponto inicial dos textos será o funcionamento de elementos semicondutores, onde se baseia a “eletrônica de estado sólido”: Diodos, transistores bipolares de junção, FETs… Outra coisa importante é a interpretação de diagramas de tempo e o entendimento dos intervalos, mínimos e máximos, que os circuitos exigem para um determinado sinal.
O primeiro componente: Diodos de junção
Um diodo é um componente com dois terminais. Um chamado “Anodo” e outro “Catodo”. Os termos foram obviamente adotados da química, onde, considerando a corrente convencional, a corrente elétrica fluirá do anodo para o catodo, mas não o contrário. Ou seja, um diodo é um “condutor” de mão única. Eis o símbolo:
Símbolo do diodo
Parece simples, huh? Mas, é claro que eu vou colocar algumas complicações aqui!
Diferente do que você pode pensar, um diodo não funciona como se fosse um curto circuito unidirecional. Ele funciona como um resistor “polarizado”. Isso quer dizer que, se a tensão entre A e K for positiva (), o diodo apresentará uma resistência elétrica baixa. Mas, se , a resistẽcnia elétrica tende ao infinito, ou seja, não circulará corrente de maneira alguma. E, como se não bastasse isso, para que o diodo comece a conduzir, a tensão tem que chegar a, aproximadamente, 0,6 V (nos diodos “de junção” PN com base em silício – existem outros, mas esses são os mais comuns).
Para entender essas regras é conveniente observar a “curva característica” de um diodo desse tipo:
Curva característica de um diodo
Onde v é a tensão e i é a corrente . Repare que até que seja igual à tensão de joelho (o gráfico assume 0,7 V, mas está amis para 0,65!), a corrente i é zero! À partir dessa tensão o diodo funciona como um resistor com baixa resitência (i cresce, de forma linear, com uma inclinação quase que de 90°!).
Se v for negativa, ou seja, se , a corrente permanecerá zerada, até que a tensão seja muito alta, onde alguma corrente “de fuga” aparecerá. Se a “tensão reversa” for muito alta, ocorrerá uma “ruptura” que, possivelemente, danificará o diodo permanentemente… Alguns tipos diferentes de diodos são feitos para trabalhar nessa região reversa (chamam-se diodos “Zener”), mas não lidarei com eles aqui.
Na prática, se o diodo está conduzindo, a tensão em seus terminais ficará em torno dos 0,6 ~ 0,7 V. Qualquer valor menor que isso e ele é como um cirtuito aberto.
Porque do nome “diodo de junção”?
Por que ele é construindo “juntando” dois cristais semicondutores, através de algum processo químico que os “soldará”. Ambos os cristais podem ser compostos do mesmo material básico (Silício, por exemplo), mas têm características químicas um pouco diferentes.
Todo material é eletricamente estável a não ser que seja feito para não sê-lo (como baterias e pilhas, por exemplo). Isso quer dizer que a quantidade de cargas não “escapa” ou “entra” facilmente nesses materiais… Por exemplo, um fio têm cargas livres que só são colocadas em fluxo através da aplicação de uma diferença de potencial nos dois extremos. A tensão, neste caso, reordena e coloca as cargas em movimento… O fio torna-se “carregado”.
Num diodo, um dos cristais é construído com um excesso de cargas negativas. O outro cristal é criado com excesso de “cargas” positivas. Não são bem cargas positivas, mas deficiência de cargas negativas ou “lacunas”… O cristal com excesso de cargas negativas recebe o nome de N e o outro de P.
Ao juntar os dois cristais temos uma junção PN, onde o cristal P está no anodo e o N no catodo. Ao aplicar uma tensão é como se o potencial no anodo “empurrasse” as lacunas (“puxando” os elétrons) do cristal P para a junção e, ao mesmo tempo, atraísse as cargas negativas do cristal N para perto da junção:
Polarização direta e reversa
Na polarização direta, como as lacunas, no cristal P, estão mais pertinhos das cargas negativas, no cristal N, fica fácil de uma carga negativa “pular” do N para o P (corrente no sentido real), mas, como os cristais são eletricamente estáveis, uma carga negativa sai do cristal P em direção ao polo positivo da bateria ε. Da mesma forma, uma carga negativa sai do polo negativo da bateria e entra no cristal N, reequilibrando-o. E, com isso, há circulação de corrente elétrica.
A diferença de potencial de 0,6 V é a tensão suficiente para “juntar” as “cargas livres” dos cristais… Mas, note, se a polarização é reversa, jamais teremos cargas livres suficientemente perto da junção e, com isso, não há circulação de corrente!
Essa “junção” é chamada de “barreira” e a tensão de condução do diodo é chamada de “potencial de barreira” ou “barreira de potencial”, na literatura.



















“uns” podem ser formados. Ou seja, cada grupo pode ser formado por 1, 2, 4, 8, 16… “uns”;

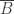


variáveis.












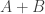










 PELs). Agora ocupa 38400 bytes por plano (
PELs). Agora ocupa 38400 bytes por plano ( ). Como o frame buffer é limitado a 128 KiB (de 0xA0000 até 0xBFFFF), esse esquema funciona muito bem, mesmo que seja complicado.
). Como o frame buffer é limitado a 128 KiB (de 0xA0000 até 0xBFFFF), esse esquema funciona muito bem, mesmo que seja complicado. ), então 40 linhas ocuparão, aproximadamente, 64 KiB que, além de caber totalmente dentro da faixa do limite de 128 KiB imposta pelo frame buffer, permite até o uso de duas “páginas”!
), então 40 linhas ocuparão, aproximadamente, 64 KiB que, além de caber totalmente dentro da faixa do limite de 128 KiB imposta pelo frame buffer, permite até o uso de duas “páginas”!
 Se IN for GND a tensão
Se IN for GND a tensão  não chegará a 0,6 V e o transístor não conduz, colocando nível alto na saída. Se IN for ligada em +5 V então o diodo de entrada não está polarizado e em corte, daí a junção base-emissor do transístor estará diretamente polaraizada, colocando zero na saída…
não chegará a 0,6 V e o transístor não conduz, colocando nível alto na saída. Se IN for ligada em +5 V então o diodo de entrada não está polarizado e em corte, daí a junção base-emissor do transístor estará diretamente polaraizada, colocando zero na saída…




 . Qualquer valor menor que esse e ele estará em corte. No circuito acima, a configuração estranha do transístor Q1 indica que ele é usado apenas como dois diodos em oposição.
. Qualquer valor menor que esse e ele estará em corte. No circuito acima, a configuração estranha do transístor Q1 indica que ele é usado apenas como dois diodos em oposição. de Q2 que fará com que V4 seja aproximadamente 0,6 V, mas a tensão é mantida nesse valor graças ao diodo em Q4.
de Q2 que fará com que V4 seja aproximadamente 0,6 V, mas a tensão é mantida nesse valor graças ao diodo em Q4.




 , então as lacunas no cristal P não estarão alinhadas (ou “juntinhas”) e as cargas do cristal N no emissor estarão caoticamente espalhadas, impossibilitando a circulação de corrente entre o coletor e o emissor.
, então as lacunas no cristal P não estarão alinhadas (ou “juntinhas”) e as cargas do cristal N no emissor estarão caoticamente espalhadas, impossibilitando a circulação de corrente entre o coletor e o emissor. que, por sua vez, controla a corrente de coletor
que, por sua vez, controla a corrente de coletor  . Pode-se inferir que o que estamos controlando, na realidade, é a resistência, imposta pelos cristais em oposição, entre o coletor e o emissor! Daí o nome do componente eletrônico.
. Pode-se inferir que o que estamos controlando, na realidade, é a resistência, imposta pelos cristais em oposição, entre o coletor e o emissor! Daí o nome do componente eletrônico. versus
versus 
 de um transístor NPN modelo BC548… O que essa curva demonstra é que
de um transístor NPN modelo BC548… O que essa curva demonstra é que  , temos:
, temos:
 , não importa qual seja a tensão
, não importa qual seja a tensão  , então a corrente
, então a corrente  temos um circuito aberto entre o coletor e o emissor. Mas, se
temos um circuito aberto entre o coletor e o emissor. Mas, se  , a corrente
, a corrente  então
então 
 ), o diodo apresentará uma resistência elétrica baixa. Mas, se
), o diodo apresentará uma resistência elétrica baixa. Mas, se  , a resistẽcnia elétrica tende ao infinito, ou seja, não circulará corrente de maneira alguma. E, como se não bastasse isso, para que o diodo comece a conduzir, a tensão
, a resistẽcnia elétrica tende ao infinito, ou seja, não circulará corrente de maneira alguma. E, como se não bastasse isso, para que o diodo comece a conduzir, a tensão  tem que chegar a, aproximadamente, 0,6 V (nos diodos “de junção” PN com base em silício – existem outros, mas esses são os mais comuns).
tem que chegar a, aproximadamente, 0,6 V (nos diodos “de junção” PN com base em silício – existem outros, mas esses são os mais comuns).
 . Repare que até que
. Repare que até que 

Você precisa fazer login para comentar.