Considere que você quer fazer um programinha que “role” um dado de 6 faces. Geralmente, alguém faz algo assim:
int r; srand( time( NULL ) ); r = rand() % 6 + 1;
A ideia é que obter o resto da divisão por 6 acarretará em valores menores que 6 (de 0 até 5) e somando 1, obtemos um dos 6 valores possíveis. Mas há um problema!
Considere que rand() retorna valores entre 0 e RAND_MAX que, em arquiteturas de 32 bits ou mais pode equivaler a 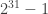
Outra forma de pensar no assunto é essa: Considere que você tenha um dado de 6 faces e queira escolher, aleatóriamente, 1 entre 4 itens (a, b, c, d). As possibilidades são: (1=a, 2=b, 3=c, 4=d, 5=a e 6=b). Os itens a e b têm mais chance de serem escolhidos (2 chances em 6, cada) porque não temos uma distribuição de valores aleatórios uniforme! A solução é nos livrarmos dos 2 últimos valores, seja “jogando” o dado novamente, colhendo apenas um dos 4 valores possíveis, ou aplicando alguma regra maluca para nos livrarmos desses dois valores. Infelizmente, a segunda hipótese não é tão simples…
Considere agora o retorno de rand() como mostrado no fragmento de código lá em cima. Obteremos valores entre 1 e 6. Acontece que temos um espaço amostral de 





A solução para esse problema não é trivial e, acredito, que nem mesmo seja possível num ambiente computacional binário. Em primeiro lugar, qualquer algorítmo que nos dê um valor aleatório conterá um valor entre 
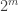



Ou seja, a cada 500 milhões (





Ahhh, mas eu sou um chato né? O erro é tão pequeno para aplicações práticas, não é? Acontece que RAND_MAX só tem 31 bits de tamanho em certos compiladores e certas arquiteturas. Outras podem usar valores muito menores, como 32767 (15 bits). De fato, a especificação ISO 9989 sugere que esse seja o valor mínimo para RAND_MAX, mas ele pode ser ainda menor!
Assim, neste caso, teríamos 5462 blocos e o último teria apenas 2 valores (como com 31 bits) e as distribuições seriam de 

Ahhhh… note que não estou considerando que rand() geralmente é implementado usando LCG que oferece menos aleatoriedade nos bits inferiores. Assim, obter o resto de uma divisão por um valor pequeno tende a criar valores ainda menos aleatórios.
